Digital Humanities in Lehrsituationen: Rahmenbedingungen - Chancen - Grenzen
urn:nbn:de:0009-5-46661
Zusammenfassung
Die Methoden der Digital Humanities (DH) bieten neue Forschungsperspektiven auf Texte. Ihre Herangehensweisen und Werkzeuge können über den Forschungsaspekt hinaus genutzt werden, da sie in entsprechenden Szenarien im schulischen und Hochschulunterricht einen Mehrwert generieren können. Die entsprechenden Konzepte bedürfen dafür einer intensiven Reflexion der Prozesse und Rahmenbedingungen, um sie gewinnbringend und didaktisch sinnvoll in Lehrszenarien übertragen zu können. Eine Integration digitaler Textzugänge im linguistischen und literaturwissenschaftlichen Unterricht ist nicht nur, wie in den Beispielszenarien aufgezeigt wird, dem Unterrichtsziel förderlich, sondern kann auch aus den offiziellen Lehrplänen abgeleitet werden. Damit sind digital-geisteswissenschaftliche Textzugänge sowohl für den schulischen Gebrauch als auch für die akademische Lehrerbildung interessant.
Stichwörter: e-learning; Lehrerbildung; Digitalität; Digitale Lehrszenarien; Linguistik; Literatur; Visualisierung; Digital Humanities; Computerphilologie
Abstract
Methods and techniques used in the field of Digital Humanities (DH) offer new research perspectives for texts and their approach as well as their tools can be used for more than just academic research. They could create added value in respective teaching scenarios in school and university education. Those concepts concerned require an intensive reflection of the processes and the frameworks, to transfer them didactically appropriate into digital teaching scenarios. The integration of ways to approach text in a linguistic and literary lesson digitally does not only support the lesson’s teaching aims, but also agrees with the official school curriculum. Therefore, the text approaches from the DH-field are interesting for teaching scenarios in schools as well as for teacher education.
Keywords: e-learning; teacher training; digitality; digital teaching scenarios; linguistics; literature; visualization; Digital Humanities; Digital Philology
Zentrale (Forschungs-)Fragestellungen innerhalb der Digital Humanities (DH) haben unter anderem die digitale Aufbereitung und Annotation von Forschungsgegenständen sowie die computergestützte Textanalyse zum Gegenstand (vgl. Thaller, 2017). Ebenso sind Aspekte unterschiedlicher Visualisierungsmöglichkeiten sowie ganz allgemein die Operationalisierung linguistischer und literaturwissenschaftlicher Fragen von Bedeutung. An diese Aspekte und Prozesse knüpft das Projekt DFd (Digitalität in den Fachdidaktiken) an, das an der Technischen Universität Darmstadt aus zentralen QSL-Mitteln bis 2018 finanziert wird. Die Projektleitung haben Andrea Rapp, Gerrit Schenk und Michael Bender übernommen, bearbeitet wird das Projekt von Lisa Scharrer. Das DFd-Projekt verfolgt das Ziel, computerphilologische Methoden und Verfahren sowie digitale Unterrichtsgegenstände für didaktische Szenarien aufzubereiten und zu nutzen und beschäftigt sich mit der Frage, inwiefern digital-geisteswissenschaftliche Methoden einen Beitrag zur Entwicklung philologischer Unterrichtsszenarien leisten können. Dabei kommen sowohl computerphilologische, also auf literarische Fragestellungen ausgerichtete, als auch computerlinguistische, auf die maschinelle Verarbeitung natürlicher Sprach ausgelegte, Verfahren zur Anwendung (vgl. Bußmann, 2008).
Die Methoden der DH bieten neue Forschungsperspektiven auf Texte und Textsammlungen, sowohl aus linguistischer und literaturwissenschaftlicher als auch aus allgemein geisteswissenschaftlicher (z.B. historischer) Perspektive. Bei diesen computergestützten Anwendungen lässt sich eine Abgrenzung zwischen quantitativem und qualitativem Vorgehen nicht immer eindeutig ziehen, da jedem quantitativen Prozess qualitative Entscheidungen vorausgehen und zugleich auch qualitative Forschung an gewissen Punkten quantifiziert werden kann. Darüber hinaus in der Sprach- und Literaturforschung hybride Ansätze häufig als fruchtbar erweisen (vgl. u.a. Mayring, 2001). Diese von der Forschungpraxis inspirierten Herangehensweisen und Werkzeuge können über den Forschungsaspekt hinaus genutzt werden, da sie in entsprechenden Szenarien im Schul- und Hochschulunterricht einen Mehrwert generieren können. Sie daher nicht auch in Wissenstransfersituationen der Lehre zu berücksichtigen, wäre eine Vernachlässigung bereits bestehender und zudem fachlich qualitativ hochwertiger Ressourcen. Die entsprechenden Konzepte dürfen jedoch nicht ohne eine intensive Reflexion in Lehrszenarien übertragen werden, da sie bestenfalls ergebnislos bleiben und sich im negativen Fall kontraproduktiv auf das didaktische Unterrichtsziel auswirken können. Neben der fachlichen Vermittlung steht dabei auch eine Heranführung der Lernenden an Datentypen und –ebenen, auch wenn zunächst die Vermittlung der Werkzeuge gewährleistet werden muss. Um den gewinnbringenden Einsatz der Szenarien zu ermöglichen, sind, auch gemeinsam mit den Lehramtsstudierenden, eine Analyse der Rahmenbedingungen und eine Reflexion der Prozesse notwendig. Ein elementarer Bestandteil ist darüber hinaus die strukturierte Herangehensweise an das Spannungsfeld zwischen technischer und fachlicher Anwendung – und damit der Frage, welche Rolle der Digitalität nun aus Lehrperspektive zukommt: Ist sie noch Methode oder bereits Unterrichtsgegenstand? Und daran anknüpfend: Ist das verwendete Werkzeug nur ein Medium, ein einfaches Hilfsmittel oder ist es bereits Teil des (Forschungs-)Prozesses, da der (wissenschaftliche) Anwender die im Hintergrund laufenden, computerlinguistischen Prozesse aktiv nutzt und reflektiert? Welche Facetten der Digitalität können in diesem Rahmen für den Unterricht aufbereitet werden? Was lernen SchülerInnen von deren multiperspektivischen Rezeptions- und Analysemöglichkeiten und welchen Einblick erhalten sie, über die reine Toolnutzung hinaus, in die unterschiedlichen Arten von Daten, Datenebenen und die bestehenden Zugriffsmöglichkeiten darauf? Die Antworten auf diese Fragen haben entscheidenden Einfluss auf die Entwicklung künftiger, didaktisch und methodisch reduzierter Lehrszenarien, wie sie im Rahmen des Lehramtsstudiums erarbeitet und diskutiert werden sollen und fördern eine kritisch-reflektierende Haltung der SchülerInnen zu den unterschiedlichen Ebenen der Digitalität.
Die bisherige universitäre Vermittlung digitaler, geisteswissenschaftlicher Methoden findet überwiegend in den DH-nahen Studiengängen (z.B. dem Bachelor-Studiengang „Digital Philology“ an der TU Darmstadt) statt. Deren Inhalte sind, dem Studienziel entsprechend, forschungsnah und überwiegend akademischer Natur. Über diese Studiengänge hinaus ist eine Integration der Methoden in den Philologien und auch in der LehrerInnenbildung weniger stark vertreten, was folglich zu einer Unterrepräsentation im schulischen Kontext führt. Das Resultat daraus, dass diese Form des digitalen Zugangs nicht ausreichend an die kommende Generation herangetragen werden kann, ist zum einen die Unkenntnis über die Existenz digital-geisteswissenschaftlicher Methoden allgemein und zum anderen der Verlust eines differenzierten Blicks auf (überwiegend) textbasierte Daten – in einer Gesellschaft, die zunehmend stark von digitalen Infrastrukturen und Daten beeinflusst wird.
Die neuen digitalen Lehrkonzepte begegnen dabei Chancen und Herausforderungen, die sich u.a. aus der Big-Data-Entwicklung ergeben und auf die SchülerInnen adäquat vorbereitet werden müssen, da die Entwicklung hin zur Digitalisierung weder im privaten, schulischen noch im kulturellen Bereich vernachlässigt werden darf.
Insbesondere korpusbasierte Verfahren, also solche, die sich mit der Analyse großer Textmengen befassen, können einen beispielhaften Mikrokosmos für diese Herausforderungen darstellen, und den SchülerInnen die Thematik näherbringen, ohne sie mit subjektiv überfordernd großen Zahlen zu konfrontieren. Dies im Rahmen des ohnehin reflexiven, metakognitiv orientierten Deutschunterrichts (Köhnen, 2011) umzusetzen, erscheint vielversprechend. Der naheliegende und nachhaltigste Weg, diese Zielgruppe zu erreichen, ist eine didaktisch sinnvolle Integration von DH-Verfahren in Wissensvermittlungsszenarien und deren Vermittlung an Lehramtsstudierende. Ist dieser Vorgang erfolgreich, kann der fächerübergreifende Einsatz, dem etliche Werkzeuge der Digital Humanities bereits auf Entwicklungsebene offen gegenüberstehen, gefördert und die entsprechenden Szenarien erweitert werden.
Um Lehramtsstudierende für computergestützte Analysen zu gewinnen, müssen diese Prozesse fachdidaktisch sinnvoll aufbereitet und in den akademischen Lehrkontext integriert werden. Damit in der weiteren Entwicklung SchülerInnen von diesen Technologien profitieren können, ist es erforderlich, neben den theoretisch-philologischen Grundlagen auch die technischen zu vermitteln. Dies erfordert jedoch mehr als die Einbindung neuer Medien in die Lehre, wie z.B. im e-Learning-Bereich, da es sich bei den digitalen Anwendungen der Geisteswissenschaften um interaktive – und nach wie vor forschungsorientierte – Systeme handelt, die unter Umständen inhaltlich reduziert und neu aufbereitet werden müssen. Dies erfordert einen hohen Grad an technischer, fachlicher und fachdidaktisch-methodischer Kompetenzsicherheit, die sich Studierende erarbeiten müssen, um in einem weiteren Schritt digital-geisteswissenschaftliche Wissensvermittlungsszenarien eigenständig zu konstruieren.
Aus fachlicher Perspektive legt das Projekt ein besonderes Augenmerk auf den digitalen Aspekt, der in den einzelnen DH-Disziplinen durchaus unterschiedlich wahrgenommen wird. Das zeigen unter anderem die ersten Erkenntnisse des Symposiums „Digitalität in den Digital Humanities“ (vgl. Habermann, 2006; Müller, 2006; und Schröter, 2006), das auf die Rolle der Digitalität in den jeweiligen Fächern eingeht. Für eine optimale Nutzung der digitalen Aspekte der Fachdidaktiken muss zunächst der Begriff der Digitalität aus den Fachdisziplinen selbst extrahiert werden. Das ist in den digitalen Geisteswissenschaften kein problemloses Unterfangen, da die Digital Humanities traditionell interdisziplinär aufgestellt sind bzw. die Projekte unterschiedlichsten geisteswissenschaftlichen Fragestellungen nachgehen. Projektgruppen aus PhilologInnen, MediävistInnen, ComputerlinguistInnen, ArchäologInnen, InformatikerInnen und HistorikerInnen sind dabei keine Seltenheit. So gestalten sich auch die Berührungspunkte mit dem Digital der Digital Humanities für die einzelnen Disziplinen, und tatsächlich auch für einzelne Projekte, unterschiedlich. In den zuvor erwähnten Konzeptpapieren der Mediävistik wird beispielsweise deutlich, dass die (durchaus kritisch diskutierte) Digitalität vor allem Auswirkungen auf die Verfügbarkeit und nachhaltige Archivierung von Artefakten hat. Hier erleichtert der digitale Zugang standortübergreifendes Arbeiten und ruft zugleich Fragen nach der Materialität, Kooperationsmöglichkeiten und den Auswirkungen der digitalen Repräsentation auf den Forschungsprozess auf (Müller, 2016). Die Germanistische Linguistik, wie von Mechthild Habermann dargelegt, nutzt Digitalität mit einem etwas anderen Schwerpunkt. Zwar beschäftigt sich auch die Korpus- und Computerlinguistik mit der Nachhaltigkeit der Daten, doch betreffen
„digitale Konzepte der Linguistik […] in erster Linie technische Fragen (Datenformate, Annotationstools und Standardisierungen), Fragen nach dem Korpusaufbau, rechtliche Fragen (Datenschutzrecht, Urheberschutz) und Fragen nach der Nachhaltigkeit (Open Access, Repositorien)“ (Habermann, 2016, S. 1).
Die beiden vorgenannten Stellungnahmen unterstützen die These, dass für die Nachbereitung digitaler Komponenten für die Fachdidaktiken der Digital Humanities Konzepte notwendig sind, die über die der Medienwissenschaft hinausgehen, denn dort, so stellt es Jens Schröter fest, ist es „evident, dass Digitalität als Gegenstand in den Medienwissenschaften in Form digitaler Medien erscheint“ (Schröter, 2016, S. 1). Das Digitale der DH hat eine Rolle inne, die zwar mediendidaktische Konzepte berührt, jedoch aufgrund der spezifischen Einsatzszenarien und Nutzungsweise darüber hinauswächst. Schröter macht auch deutlich: „obwohl digitale Medien der offensichtliche Gegenstand der Medienwissenschaft sind, ist theoretisch eine gewisse Bandbreite von Begriffen der ‚Digitalität‘ festzustellen.“ (ebd.) Ein viertes Feld, auf das Busse eingeht, ist das Verhältnis der DH zur angewandten Informatik. Nicht ganz überraschend lässt sich hier feststellen, dass digital-geisteswissenschaftliche und informatische Lehrkonzepte durchaus Herausforderungen der Lehre und Wissensvermittlung teilen, etwa wenn es um die Abgrenzung von Fach- und Methodenkompetenz geht (Busse, 2002).
Die Klärung der Frage, wie und unter welchen Umständen DH-Methoden den sprachwissenschaftlichen Unterricht bereichern können, ist das Grundgerüst für eine sinnvolle Einbettung von Computerphilologie und Computerlinguistik. Der vielfach kritisierte Medieneinsatz um des Medieneinsatzes Willen ist auch in diesen Szenarien nicht zielführend, wenn er keinen Mehrwert für die Vermittlung des Unterrichtsgegenstands schafft.
Aus fachlicher Perspektive muss entschieden werden, wann ein digitaler Zugang tatsächlich Mehrwert für die Lehre generiert, oder präziser: inwiefern er etwas leisten kann, das manuell nicht möglich ist, deutlich aufwendiger wäre oder eine eingeschränktere Perspektive vermitteln würde. Dies trifft besonders häufig auf die Arbeit mit längeren Texten und größeren Textmengen zu. Diese sogenannten Korpora sind Sammlungen von Texten, die unter einem bestimmten Forschungsaspekt vereint und dementsprechend aufbereitet werden (Bußmann, 2008). Doch auch wenn das angestrebte Lehrziel keine Arbeit mit umfangreichen Korpora notwendig macht, es sich also um Arbeiten an Einzeltexten handelt, bieten digitale Ansätze eine Reihe manuell nicht möglicher Textzugänge an. Dies können beispielsweise Visualisierungen, automatische Auszeichnungen oder quantitative Auswertungen sein. Der entstehende Mehrwert ist jedoch durchaus abhängig von der Zielgruppe – und der fachlichen Komplexität der Anwendung, insbesondere was die verwendete Terminologie betrifft. Ausreichende Kenntnis über vorhandene und angestrebte philologische Kompetenz und Lernziele hilft bei der Auswahl der digitalen Zugänge und macht verwirrende oder zu komplexe Analyseschritte rechtzeitig identifizierbar.
Aus technischer Sicht ist der Schwerpunkt im Lehrkontext ebenfalls (auch) auf die Zielgruppenanalyse und zudem auf die bestehende technische Infrastruktur zu richten. Da Medien- und Technologiekompetenz zu einer gewissen definitorischen Unschärfe neigen und darauf ausgerichtete Untersuchungen, wie beispielsweise die JIM und KIM Studie (Feierabend, Plankenhorn & Rathgeb, 2015), einen kommunikationswissenschaftlichen Ursprung haben, erweist es sich als sinnvoll, gezielter Informationen einzuholen, insbesondere was die Erfahrung in der Einarbeitung mit neuer Software betrifft. Unter gewissen Umständen können so auch Lernenden-Erfahrungen im Social-Media-Bereich die Vermittlung einiger Digital-Humanities-Konzepte begünstigen, wie beispielsweise das Prinzip des Hash-Taggings auf Twitter, das in den Grundzügen einer rudimentären Textannotation entspricht. Vorhandenes Wissen auf den wissenschaftlichen und schulischen Kontext zu übertragen, kann dadurch erleichtert werden.
Weniger beeinflussbar ist in der Regel die bestehende technische (Hardware-)Infrastruktur, sowohl an Schulen als auch an Hochschulen. Das immer häufiger genutzte BYOD(Bring-your-own-device)-Modell ist für digital-philologische Lehrszenarien nur stark eingeschränkt anwendbar, da Smartphones oftmals für die Anwendung der entsprechenden Werkzeuge ungeeignet sind. Gründe dafür sind die geringe Bildschirmgröße, die die Textarbeit deutlich unkomfortabler macht, und der geringe Speicherplatz, um umfangreiche Textdateien zu speichern, aufzubereiten, in das Programm zu laden und dessen Ergebnis zu sichern. Hier geraten erfahrungsgemäß auch Tablets an ihre Grenzen.
Ein besonderes Augenmerk erfordern die technische und fachliche Tool-Wahl und eine korrekte Tool-Einführung, welche entscheidend für den Erfolg der Lerneinheit sind. Mindestens ebenso relevant wie die fachlichen Aspekte der Entscheidung für oder gegen ein computerphilologisches Werkzeug, sind Programmcharakteristika wie beispielsweise eine breite Plattform-Akzeptanz. Zudem eignen sich Programme mit einem Graphical User Interface (GUI) deutlich besser als Software, die über die Kommandozeile gesteuert wird, oder die Eingabe einer Programmiersprache wie Python erfordert. Da etliche der frei verfügbaren Programme zunächst für den Forschungskontext entwickelt wurden und bereits ein gewisses Vorwissen (sowohl fachlich als auch technisch in unterschiedlichem Maße) voraussetzen, ist es entscheidend, die Lernenden hier nicht methodisch zu überfordern, da der zentrale Unterrichtsgegenstand philologischer und nicht technischer Natur sein soll. Damit ein Werkzeug erstens nicht zum Hindernis und zweitens als Hilfsmittel akzeptiert wird, muss die Tool-Wahl durchdacht getroffen werden. Dazu gehört eine gute (im Notfall selbst zu erstellende) zielgruppengerechte Dokumentation, die das entsprechende terminologische Niveau der Lernenden aufgreift, sowie unter Umständen auch die Möglichkeit, auf technischen Support zurückgreifen zu können. Die hier beschriebenen Aspekte zeigen deutlich, wie entscheidend es ist, den Studierenden einen guten Einstieg und eine Auswahl an Tools vorzustellen, die dann auch intensiv reflektiert werden, um die Stärken und Schwächen (beispielsweise Probleme bei nicht satzbasierten Texten, Schwierigkeiten mit der Verarbeitung von Fremdsprachen, Vor- und Nachteile eines besonders übersichtlichen Tag-Sets etc.) der Tools zu kennen und zu nutzen – denn letztlich soll das Tool zum Unterrichtsgegenstand passen und nicht der Unterrichtsgegenstand an das (bekannte, vertraute) Tool angepasst werden.
Der folgende beispielhafte Workflow zur Vorbereitung einer Unterrichtseinheit (vgl. Abbildung 1) greift in einem ersten Ansatz auf, welche zusätzlichen Aspekte durch die Lehrkraft berücksichtigt werden müssen (grau) und an welchen Aufgaben sich die Lernenden beteiligen (rot). Je nach informatischer Vorbildung, Wissensstand und Lernziel können sich die roten Felder ausweiten, wenn Lerner beispielsweise auch am Prozess der Tool-Wahl aktiv mitwirken.
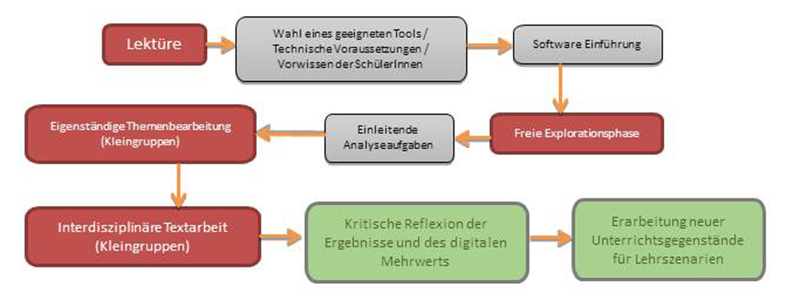
Abbildung 1: Beispielhafter Workflow zur Arbeit mit digitalen Textanalysetools (im Rahmen der Lehrerbildung)
Die Reflexionsphase (grün) bezieht sich auf die Erarbeitung der Szenarien im Rahmen der Lehrerbildung. Hier werden die Studierenden mit dem vorgenannten Lehrszenario konfrontiert und erhalten die Möglichkeit, die digitalgestützte Unterrichtseinheit zu erfahren, kritisch auf ihren Mehrwert hin zu reflektieren und im weiteren Verlauf selbständig entsprechende Szenarien aufzubauen, sowie mithilfe digitaler Methoden die fachdidaktische Auswahl der Unterrichtsgegenstände zu erweitern.
Auch hier stellt sich die besondere Herausforderung, eine geeignete Kombination technischer und fachlicher Aspekte zu erreichen, da sich beide auf die produktive und rezeptive Arbeit an und mit dem Unterrichtsgegenstand auswirken. Eine vollständige Vermittlung der Hintergründe, wie es im Rahmen eines computerlinguistischen oder computerphilologischen Studiengangs angebracht ist, würde den Rahmen des Lehramtsstudiums übersteigen – dementsprechend noch einmal reduzierter und an die Zielgruppe angepasst, muss die Übersetzung theoretisch-philologischen Wissens in technische Befehle im modernen, digitalgestützten Sprach- und Literaturunterricht erfolgen.
Gründe, die hier besprochenen Konzepte und Methoden im Rahmen des Lehramtsstudiums aufzugreifen, finden sich explizit und implizit in den entsprechenden gymnasialen Lehrplänen der Fächer Deutsch, Geschichte und Informatik. Dass Studierende aus DH- und DH-nahen Fächern diese Prozesse kennenlernen und verstehen müssen, ist selbstverständlich, doch neue digitale Konzepte in die Lehrerbildung und damit in den Schulunterricht zu integrieren, mag zunächst mitunter redundant erscheinen, wo doch die modernen Medien ohnehin zunehmend Einzug in das Klassenzimmer halten. Dieser Eindruck ist der bereits erwähnten Unschärfe des Digitalitäts-Begriffs geschuldet, denn nicht alles Digitale (oder digital Mediale) ist auch ein Teil der Digital Humanities im engeren Sinne. Daher muss im Rahmen des Schulunterrichts bewusst eine neue Herangehensweise an digitale Anwendungen vermittelt werden, die auch durch Methoden und Werkzeuge der Digital Humanities zu leisten sind. Der (hessische) gymnasiale Lehrplan zeigt, dass sich digitale sprachwissenschaftliche Konzepte durchaus eignen, um SchülerInnen an die geforderten Lehrplanziele heranzuführen. Der Lehrplan Deutsch beispielsweise wünscht „die exemplarische Einführung in die Denk- und Arbeitsweisen der Wissenschaft“ und hat das Ziel, „Problemmanagement und Neugier auf Lösungen zu verstärken, sowie die Bereitschaft fördern, Hypothesen zu entwickeln, sie zu verteidigen und gegebenenfalls zu revidieren“ (Hessisches Kultusministerium, 2010b, S. 4) – ein entsprechendes digitales Szenario hätte hier beispielsweise die Funktion, als objektives Analysetool die subjektiven Hypothesen zu verifizieren oder zu verwerfen. Darüber hinaus sollen „Methoden der Texterschließung […] den SchülerInnen helfen, textinterne Elemente und Strukturen […] aufzudecken“ (ebd.). Eine informatische Herangehensweise ist (zumindest im Fach Deutsch) nicht explizit gefordert, doch die neuesten Methoden der Texterschließung kennenzulernen, seien sie nun analog oder digital, folgen dem Sinn dieses Absatzes. Besonders notwendig erscheint eine rasche Integration moderner (digitaler) Herangehensweisen, wenn man bedenkt, dass „die Innovationszyklen der Institution Schule […] um ein Vielfaches länger als die der Erwachsenenbildung [sind]“ (Busse, 2002, S. 133), die positiven Auswirkungen durch eine konkrete Umsetzung im Schulunterricht also erst Jahre später zum Tragen kommen.
Zudem bietet sich die Vermittlung fächerübergreifender Projektkonzepte an der Schnittstelle des Deutsch- und Informatikunterrichts an. In diesem Bereich die Methoden der DH ebenfalls zu nutzen, ist zielführend, da der Lehrplan die „Reflexion des Verhältnisses von Mensch und Technik“ (Hessisches Kultusministerium, 2010a, S. 4) fordert und erkennt, dass „[d]ie Kenntnis der Möglichkeiten, Grenzen und Gefahren beim Einsatz von Informatik“ (ebd.) Anlass dazu gibt, dass sich SchülerInnen „mit normativen und ethischen Fragen, die z.B. den Zugriff auf und die Nutzung von Information sowie den Umgang mit dem Urheber- und Datenschutzrecht betreffen“ (ebd.), beschäftigen. Als Ausgangspunkt für eine entsprechende Diskussion eignen sich digital-geisteswissenschaftliche Szenarien. Die SchülerInnen sollen sich dabei, wie ebenfalls im Lehrplan gewünscht, „selbstständig und kreativ in die Gestaltungsmöglichkeiten mit Informatiksystemen ein[...]arbeiten und zur Lösung von Problemen adäquate Werkzeuge [auswählen und anwenden].“ (ebd.).
Die Computerphilologie beschäftigt sich mit der computergestützten Literaturanalyse und den Aspekten der Computerlinguistik. Nachfolgend werden zwei unterschiedliche Szenarien beispielhaft ausgearbeitet, da die entsprechenden Übertragungsbereiche Literaturunterricht und Sprachunterricht unterschiedliche Herangehensweisen, Kompetenzziele und Schwerpunkte behandeln. Die genannten Szenarien sollen im Rahmen der akademischen Lehrerbildung durchgeführt, reflektiert und gemeinsam überarbeitet werden, wobei der Unterrichtsgegenstand der Szenarien selbst (nicht der, der sie beinhaltenden lehrerbildenden Lerneinheit) für die Zielgruppe Schüler an der Gymnasialen Oberstufe ausgelegt ist.
Der Literaturunterricht eignet sich, um mithilfe von computergestützten Visualisierungen theoretisches Vorwissen anhand ausgewählter Beispiele, also aktueller Unterrichtslektüren, zu veranschaulichen. Dabei kann das theoretische Vorwissen zu Genre, Textaufbau oder Autorenstil anhand vorhandener Textmerkmale, der Wortwahl und dem Auftreten der handelnden Figuren praxisbezogen abgeprüft und diskutiert werden. Dieser (aus Lernerperspektive) neue Blick auf den Text hilft dabei, das Gelesene (auch) quantitativ nachzuvollziehen und mit der entsprechenden Theorie zu verknüpfen. Darüber hinaus können neue, zuvor nicht erfasste Informationen zu sprachlichen Phänomenen gewonnen werden, die im klassischen Leseprozess der Aufmerksamkeit des Rezipienten entgehen und erst durch quantitative Analysen bzw. deren Visualisierung sichtbar werden. Die zentrale Kompetenz des Literaturunterrichts ist die Förderung von Entwicklung der Lesekompetenz und des Textverstehens (Leubner, Saupe & Richter, 2010), daher soll an dieser Stelle betont werden, dass das vorgestellte Szenario die klassische Lektürearbeit lediglich bereichernd ergänzt, jedoch nicht ersetzt. Digitale Szenarien dieser Art ermöglichen dabei, die Aufmerksamkeit der Lernenden auf textinterne Phänomene zu lenken, die künftig im klassischen Leseprozess mit vergleichbaren Texten berücksichtigt werden können und so die Lesekompetenz auch nachhaltig bereichern.
Ein geeignetes Voyant-Beispiel ist die Darstellung ausgewählter Kookkurenzen des Lektüretextes (vgl. Abbildung 2). Kookkurenzen weisen auf häufig miteinander auftretende Worte (Tokens) hin (vgl. Bußmann, 2008). Die Auswahl der zu analysierenden Worte, der Tokens, die aktiv in den Analyseprozess eingespeist werden (Tokens in grün), ist hier von zentraler Bedeutung.

Abbildung 2: Kookkurenz-Visualisierung von Shakespeares „Romeo und Julia“ mit Voyant. Das *-Symbol ermöglicht die Erfassung unterschiedlicher Wortendungen, also z.B. „Romeo/Romeos“
Voraussetzung, um diese digitalen Szenarien mehrwertgenerierend in die Lektürearbeit zu integrieren, ist ein zuvor erworbenes, gründliches Verständnis des gelesenen Textes, wobei die Visualisierung der Kookkurenzen die Wichtigkeit des Close Reading-Prozesses unterstreicht und zugleich als inhaltliche Verständniskontrolle dienen kann. Insbesondere das Auftreten der assoziierten Kookkurenzen (Tokens in rot), welche die relevanten Kookkurenzen der manuell ausgewählten Worte (grün) anzeigen, können eine Diskussionsgrundlage bieten, um sich mit den textinternen Handlungen reflektierend auseinanderzusetzen. Aber ebenso, um die verwendete Sprache in ihrer Ganzheit zu erfassen, zu erforschen und zu vermitteln und so auch sprachwissenschaftliche Aspekte zu verknüpfen, um die einzelnen Teilbereiche des Deutschunterrichts als Komplettsystem zu begreifen.
Mit Hilfe einer Manipulation der Parameter und einer durchdachten Auswahl an Schlagworten kann der Plot der Tragödie in einem verzerrten Bild erscheinen – ein Aspekt der didaktisch aufbereitet durchaus nutzbar ist und die Vielfalt möglicher Übungsaufgaben erweitert. Bei einer ‚klassischen‘ Nutzung und einer inhaltlich sinnvollen Auswahl der Tokens kann ein solches Cluster als Visualisierung die Zusammenhänge der Geschichte veranschaulichen und die Grundlage einer Reflexion des Geschehens ergeben – etwa wenn nicht alle erscheinenden (roten) Token erklärt werden können. Bewusste Manipulationen können dann die Wahrnehmung eines Plots beeinflussen und sogar verfälschen, daher können sie im Umkehrschluss zu einem besseren, fachübergreifenden Verständnis für Informationsaufbereitung führen. Aus literarischer Perspektive tragen diese Manipulationsmöglichkeiten dazu bei, eine neue – nicht zwangsläufig falsche – Sicht auf die Handlungen der Tragödie zu werfen, indem z.B. zeitweise Nebencharaktere fokussiert werden und deren Beziehungen untereinander zu diskutieren sind.
Beispiel Arbeitsaufgaben:
-
Bearbeiten Sie den Text „Romeo und Julia“, indem Sie die Kookkurenzen (Default-Einstellung) analysieren.
-
Wie ist das Verhältnis zwischen dem Token „Wärterin“ und „fräulein“?
-
Wer oder welche Personengruppe wird/werden unter diesen Begriffen erfasst?
-
Auf welche Person(en) kann sich das Token „Capulet“ beziehen?
-
Wie müssen Sie das Cluster manipulieren, um das Verhältnis von Tybalt, Mercutio und dem Wort „Kampf“ visualisiert zu bekommen?
-
Diese Arbeitsaufgabe kann für den Deutschunterricht genutzt werden, richtet sich in diesem Kontext jedoch an Studierende, die das Tool im Selbstversuch erfahren. Textsortenwissen und sprachliche Erfahrung wird hier die Antwort liefern, dass Capulet sowohl als Familienname als auch stellvertretend für den Familienvater verwendet wird und sich daher auf unterschiedliche Personen beziehen kann.
Anhand der Visualisierung eröffnet sich dem Lehrenden eine vielfältige Unterrichtsgrundlage, die von der Überprüfung theoretischen Vorwissens
-
Wie zeichnet sich der Plot ab?
-
Entspricht das der Textsorte?
bis hin zu technisch-fachlichen Diskussionen
-
Wonach genau sucht das Programm?
-
Welche Rolle spielt die Morphologie?
reicht, bei der die Arbeitsweise der Software nicht gänzlich von den fachlichen Aspekten getrennt werden kann.
Die Grundlage der computergestützten, literaturwissenschaftlichen Textarbeit bildet zunächst die korrekte Einführung des digitalen Textzugangs, das ein späteres produktives Arbeiten und Lernen ermöglicht. Die Software selbst und auch die hier verwendete Visualisierung sind demnach Bestandteil der didaktischen Einheit und müssen entsprechend aufgearbeitet werden, um einen geeigneten Rahmen für die Arbeit mit dem literarischen Unterrichtsgegenstand zu schaffen. Daher ist es notwendig, die Lernenden an das Werkzeug heranzuführen und technische sowie fachliche Handlungsfähigkeit aufzubauen. Das hier vorgestellte Voyant-Tool (Sinclair & Rockwell, 2016) eignet sich für unterschiedliche Zielgruppen, da die Nutzeroberfläche nutzerfreundlich, optisch ansprechend und weitestgehend intuitiv gestaltet ist. Zudem ist es online und kostenfrei verfügbar, sodass Störfaktoren wie Lizenzgebühren oder ein Installationsaufwand entfallen.
Dieses literaturwissenschaftlich geprägte Szenario bedarf demnach der Behandlung dreier, ineinander übergreifender Lernprozesse:
-
die Tooleinführung und die (technische Generierung) der Visualisierungen
-
die Einführung der Visualisierungsformen als fachdidaktischer Inhalt und deren (fachlicher) Generierung
-
die Anwendung des Lektüre- und Fachwissens als fachdidaktischer Inhalt bei der Interpretation der Visualisierung.
So schließt an die technische Einführung eine zweite Einleitung mit fachlich-methodischem Schwerpunkt an, die auf den rein technischen Lerninhalten aufbaut. Die Lernenden wissen mittlerweile, wie sie das Tool bedienen können, doch aus fachlicher Perspektive ist wichtig, dass sie auch verstehen, wie das Tool arbeitet und welche Textverarbeitungsprozesse im Hintergrund stattfinden. Die Aufarbeitung der Wechselwirkungen zwischen informatischer Textverarbeitung durch die Software und fachlichem Zugang durch den Lerner (oder Textforscher) bietet dabei bereits eine Grundlage für sprachreflektierende Unterrichtseinheiten.
Die Möglichkeiten einer Manipulation der Analyseprozesse und die damit verbundenen Auswirkungen auf das Ergebnis, wie sie bereits zu Beginn des Kapitels dargelegt wurden, ermöglichen neue Lernaufgaben, die über ein Trial-and-Error-basiertes Lernen hinausgehen, doch dafür müssen die vorgenannten Rahmenbedingungen sowohl technisch als auch fachlich erfüllt sein. Insbesondere für den dritten Lernaspekt, die Anwendung des Lektüre- und Fachwissens bei der korrekten Interpretation der Visualisierung, ist das Hintergrundwissen entscheidend. Dieser finale Aspekt bietet über die fachliche Komponente hinaus eine Verknüpfung mit bereits vorhandenen Erfahrungen im Umgang mit Visualisierungen, Statistiken und Grafiken an.
Ein visualisierungsgestützter Literaturunterricht zielt darauf ab, Visualisierungen, Software und Computerapplikationen allgemein als unterstützendes Tool wahrzunehmen, das Prozesse beinhaltet und anwendet, die einer kritischen Reflexion bedürfen. Computergestützte Literaturanalyse kann neue Perspektiven auf einen Lektüretext eröffnen, neue Interpretationsanstöße sowie Diskussionsgrundlagen ermöglichen und zugleich die Möglichkeit bieten, subjektiv-intuitive Interpretationen als solche wahrzunehmen und mit quantitativen Methoden zu überprüfen. Neben dem strukturierten Arbeiten an Texten stehen die Lernenden auch vor der Aufgabe, sinnvolle und problemlösungsorientierte Workflows zu entwickeln. So kann die manuelle und digitale Herangehensweise an Texte geschult werden, ohne die qualitative Arbeit zu vernachlässigen und durch einen rein quantitativen Zugang zu ersetzen. Neben den (computer-)philologischen Kompetenzen werden zudem sowohl Teamarbeit als auch Medien-Informationskompetenz geschult, da sich Kompetenzen, die im Rahmen der Visualisierungsinterpretation erworben und ausgebaut werden, auch auf alltägliche digitale Informationsdarstellungen übertragen lassen.
Einen Mehrwert schafft die Integration des Visualisierungstools im Literaturunterricht demnach auf unterschiedlichen Ebenen. Zunächst ermöglicht es, aufgrund der Digitalität, einen interdisziplinären Zugang zu einem klassischen Thema des Deutsch- bzw. Germanistikunterrichts, was mit einem detaillierteren Verständnis für technische und fachliche Prozesse einhergeht.
Der Perspektivenwechsel unterstützt Lernende dabei, im wahrsten Sinne des Wortes ‚einen neuen Blick‘ auf den Text zu bekommen und damit dann sehr viel präziser und gezielter nach Auffälligkeiten zu suchen. Nutzbar ist in den digitalen Szenarien der, hier bewusst abstrakt verstandene, Effekt der didaktisch motivierten Verfremdung (Budde, 2011), da durch eine bewusste Distanz zum Text und damit zur Sprache deren Reflexion begünstigt wird.
Zudem ermöglicht dieser perspektivische Wechsel, Studierende (und nachfolgend SchülerInnen) auf Aspekte aufmerksam zu machen, die ohne diese Verfahren keine Aufmerksamkeit erregt hätten, da deren Existenz bzw. Relevanz erst quantitativ sichtbar wird. Solche Auffälligkeiten können anhand des theoretischen Überbaus der Unterrichtseinheit überprüft, erklärt und diskutiert werden, um das vorhandene Wissen zu vertiefen.
Ein Beispiel für eine solche quantitative Relevanz von zunächst unauffälligen sprachlichen Aspekten sind die sogenannten Funktionswörter. Deren auf den ersten Blick unscheinbares Vorkommen fällt während des klassischen Leseprozesses kaum auf, für ein digitales Lehrszenario können sie jedoch zugleich Bereicherung und Hindernis sein, da sie in Häufigkeitsanalysen ‚informationsreichere‘ Worte auf die hinteren Ränke verweisen. Jene Token (hier: Wörter) sind ein passendes Beispiel, dass übersehbare, weil gewöhnlich wirkende, Phänomene wie unauffällige Wortgruppen, die nicht zu den klassischen Stilmitteln gehören, erst durch Quantifizierung ins Bewusstsein der Lernenden rücken können. Methodisch wirken diese Wort-Tokens zunächst störend, da sie einen prominenten Platz in den vorderen Rängen einer quantitativen Häufigkeitsverteilung einnehmen, für sprachreflexive Einheiten bieten sie jedoch einen willkommenen Anlass, um deren fachliche Funktion und Bedeutung zu diskutieren, ehe eine Entscheidung getroffen wird, diese ggf. aus der Analyse herauszuhalten. Auch die Frage, welche Wortarten oder Tokens die zuverlässigsten Träger des Textinhaltes sind, lässt sich in diesem Szenario aufarbeiten. Während der Unterrichtseinheit erfolgt regelmäßig eine systematische Reflexion des Tools, der Darstellung und des Informationsgehalts.
Direkt nach dem Laden der Lektüre erstellt das Voyant-Programm zunächst einige Visualisierungen (darunter auch die hier vorgestellte Kookkurenzen-Visualisierung) und Tabellen mit einer voreingestellten (Default-)Auswahl von Tokens aus dem Text. Im weiteren Verlauf der Textarbeit können jedoch alle Schlagworte frei gewählt bzw. gelöscht werden. Durch einen ersten Trial-and-Error-Prozess lernen die Studierenden bzw. Schüler*innen die Auswahl ihrer Schlagworte zu erweitern, zu begrenzen und zu überarbeiten, um das Ergebnis anhand ihres Lektürewissens zu optimieren. Insbesondere der Umgang mit den technischen Möglichkeiten, auf sprachwissenschaftliche Fragestellungen zu reagieren und diese effektiv zu operationalisieren, wird geschult, wenn beispielsweise die Notwendigkeit auftritt, unterschiedliche morphologische Varianten in die Analyse einzubeziehen. Eine solche Manipulation kann durch das Asterisk-Symbol (*) erreicht werden, das die Lernenden fordert, ihr sprachliches und literarisches Wissen den spezifischen Text betreffend zu nutzen, um beispielsweise sowohl das Token (hier: das Wort) „Julia“, als auch „Juliens“ oder auch unterschiedliche Variationen von „Romeo“ („Romeos“, „Romeo’s“) zu erfassen.
Der Transfer sprachlicher und literaturwissenschaftlicher Fragestellungen in für das System sinnvoll operationalisierbare Anweisungen ist eine anspruchsvolle Aufgabe, der sich die Lernenden (Studierende wie Schüler*innen) mit dem Tool nähern, ohne mit einer Programmiersprache konfrontiert zu werden. Dennoch kann diese Art der Textanalyse bei Interesse durchaus einen Einstieg in komplexere, computerphilologische Prozesse bieten. Darüber hinaus kann, sowohl implizit als auch explizit, die Methodenkompetenz im kritischen Umgang mit den Visualisierungsergebnissen dieses Tools geschult werden. Erkenntnisse, die sich auf andere Datendarstellungsformate übertragen lassen und eine reflektiertere Grundhaltung zum einen gegenüber maschineller Sprachverarbeitung (mit besonderem Hinblick auf die Semantik) und zum anderen gegenüber der Aussagekraft und Manipulierbarkeit von Ergebnisdarstellungen fördern.
Das zweite Szenario entstammt dem computerlinguistischen, sprachwissenschaftlichen Bereich und kann zur Unterstützung einer Unterrichtseinheit mit dem Schwerpunkt Grammatik (hier insbesondere das Verhältnis von Wortarten und Syntax) eingesetzt werden. Sprachdidaktische (und auch methodische) Konzepte für den Grammatikunterricht stehen in der Regel vor der Hürde, dass der Lernstoff von der Zielgruppe als trocken und stark theoretisch erfahren wird (Köhnen, 2011; Budde, 2011). Hier schaffen digitale Zugänge Abhilfe auf methodischer und fachdidaktischer Ebene, da Tools wie das hier verwendete UAM Corpus Tool von Mick O’Donnell (O’Donnell, 2016, vgl. Abbildung 3 und 4) eine Vielzahl neuer Perspektiven liefern, die zwar zunächst auch visuelle Zugänge ermöglichen, fachlich aber deutlich darüber hinausgehen. Als Textgrundlage dient in diesem Beispiel das erste Kapitel von Effie Briest, das ebenfalls über das Gutenberg-Projekt als Plaintext-Datei vorliegt.
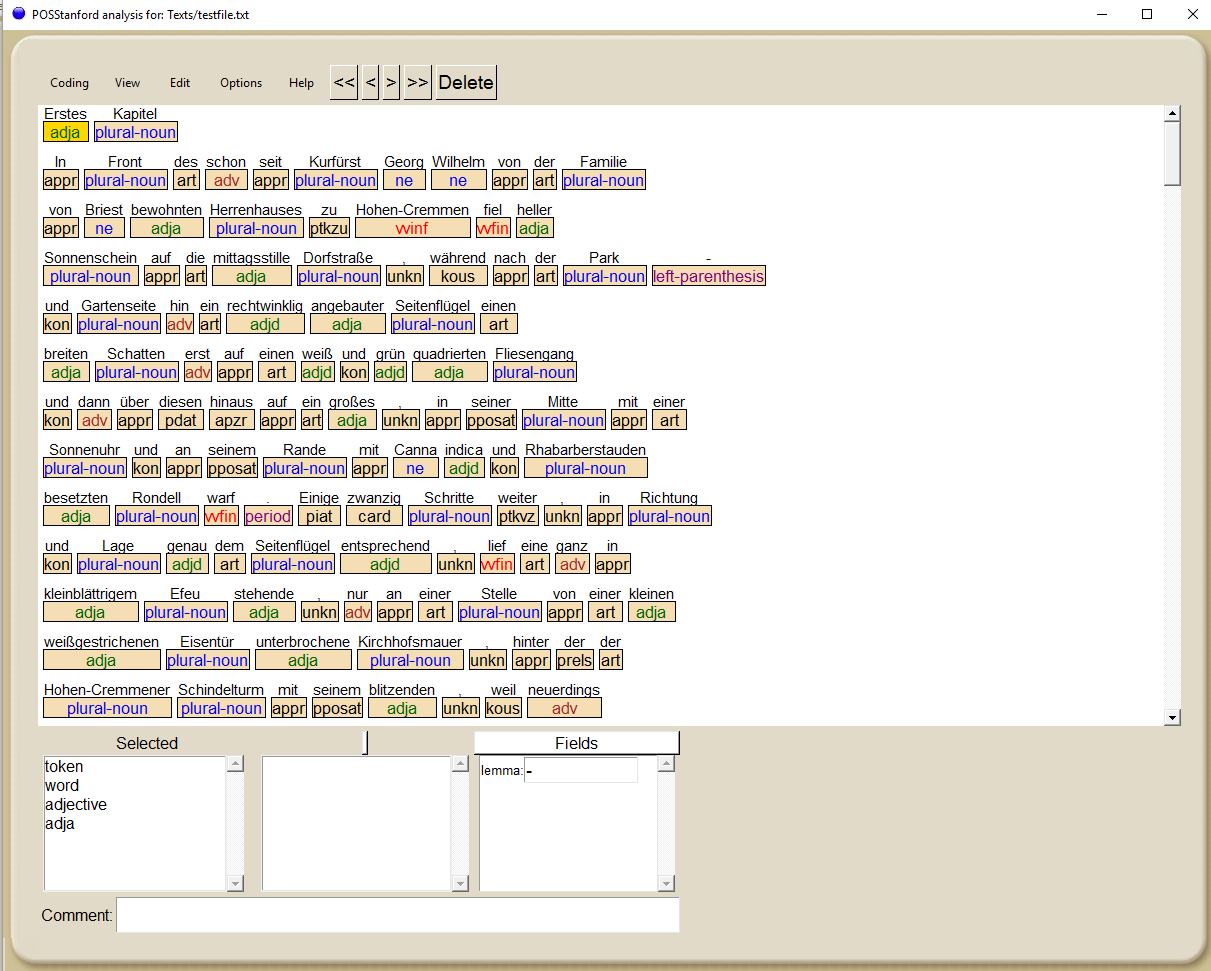
Abbildung 3: Beispiel Part-of-Speech Analyse von Fontanes „Effie Briest“ mit dem UAM CorpusTool
Die Anwendung des Tools gestaltet sich nutzerfreundlich, dennoch ist eine sorgfältige und nachhaltige Einführung, wie bereits im vorherigen Szenario benannt, notwendig. Wie bereits erörtert wurde, unterliegt die Toolwahl auch vergleichsweise profanen Kriterien, wie der Komplexität des Installationsvorganges. Während das Voyant-Tool über einen Online-Webbrowser ohne Mehraufwand gestartet werden kann, sind für das UAM-Corpus-Tool Vorarbeiten notwendig. So müssen nicht nur das Tools selbst, sondern auch die aufzurufenden Anwendungen installiert sein – beispielsweise der TreeTagger (der wiederrum eine aktuelle Java-Version benötigt).
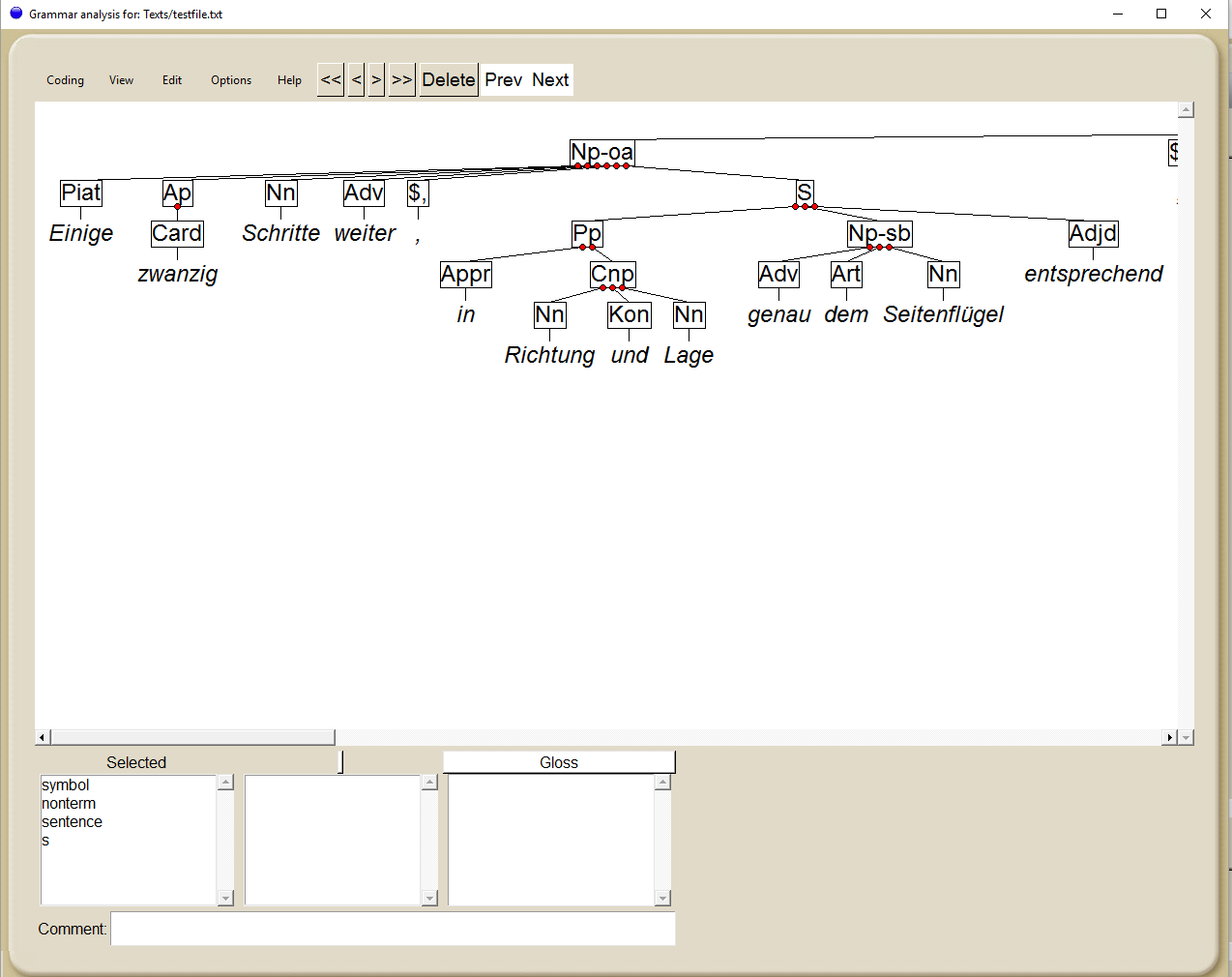
Abbildung 4: Beispiel Satzstruktur-Analyse von Fontanes „Effie Briest“ mit dem UAM CorpusTool
Der grammatische Vermittlungsgegenstand, beispielsweise die Unterscheidung zwischen Wortarten, wird durch den digitalen Zugriff erfahrbar – und interaktiv. Da über ein einzelnes Dokument mehrere Annotationslagen (Layer) gelegt werden können, steht einem Trial-and-Error-basierten Unterricht nichts im Wege. Nachfolgende Möglichkeiten eröffnen durch die computergestützte Wortartenanalyse neue Perspektiven für die Lehre.
Zunächst klingt diese Methode nach einem klassischen Grammatikunterricht – markieren Sie die Worte und benennen Sie die Wortart. Doch der computerlinguistische Zugang ist mehr als nur ein neues Medium für eine prinzipiell bereits bekannte, analoge Übungsform: Er unterstützt darüber hinaus die Entwicklung eines individuellen Tag-Sets, also eigener hierarchischer Modelle, die festhalten, welche Tags (Auszeichnungen) verwendet werden sollen, um dem Unterrichtsziel gerecht zu werden. Das erleichtert die manuelle Textannotation erheblich und unterstützt dabei zugleich, das Wissen um die Wortarten gezielt zu strukturieren – und individuelle Schwerpunkte zu setzen. Hierbei ist es notwendig, dass die Lernenden ihr vorhandenes Wissen einsetzen, um ggf. voreingestellte Annotations-Layer zu manipulieren oder um eigene zu generieren – wobei der Schwerpunkt sehr unterschiedlich gesetzt sein kann.
Die Möglichkeit, Layer (also Schichten oder Annotationsebenen, vgl. Abbildung 5) auf Satzebene, Satzteilebene und Wortebene parallel zu kreieren, erfordert bewusste und durchdachte Arbeitsentscheidungen und ist das Resultat einer guten Strukturierung des eigenen Wissens. Hierbei kann das Arbeitsziel (Beispielsweise in Gruppenarbeit alle Adjektive und Adverbien zu annotieren) fachliche, kommunikative und organisatorische Lernziele erfüllen, wenn unterschiedliche Kategorie-Ebenen verlangt werden, also beispielsweise einzelne Adjektive weiter unterteilt werden sollen. Dabei stellt sich die Frage, ob separate Layer für Adjektive und Adverbien erstellt werden sollen – oder ob es sinnvoller ist, eine großkörnige Annotation (Adjektive und Adverbien) sowie mehrere feinkörnigere Annotationen zu generieren und die Frage, wie Mehrfachzuordnungen umgesetzt werden können. Dieser Grammatikzugang unterstützt und benötigt eine durchdachte Reflexion sprachlicher Aspekte.
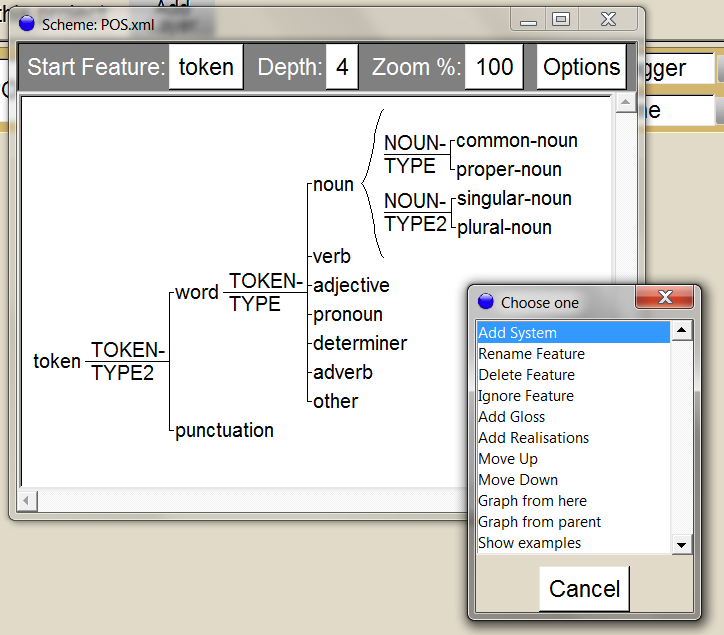
Abbildung 5: Part-of-Speech Annotationsschema im UAM CorpusTool
Je nach Wissensstand der Zielgruppe kann es den Unterricht bereichern, automatisierte Tagger zu verwenden, die entsprechende Texte ohne Zutun der Anwender mit den entsprechenden POS(Part-of-Speech)-Tags versehen. Interessant ist dabei, dass es eine Vielzahl unterschiedlicher Tag-Sets (und auch Tagger) gibt, deren Schwerpunkte ähnlich vielfältig sind, wie es die Facetten eines Unterrichtsszenarios sein können (vgl. dazu Rapp, 2017).
Im weiteren Verlauf können mithilfe verschiedener Annotations-Ebenen mehrere Aspekte der konzeptionellen Schriftlichkeit parallel bearbeitet werden, um die entsprechenden sprachlichen, orthographischen, grammatischen, lexikalisch-semantischen sowie Textsorten-Kenntnisse zu fördern und in ihren Wechselwirkungen zu begreifen (Köhnen, 2011).
Insbesondere die reflexive Sicht auf die eigene Sprache kann durch den digitalen Zugang erleichtert werden. Da Sprache im Grammatikunterricht (und auch im Literaturunterricht) zugleich Kommunikationsmedium und Unterrichtsgegenstand ist, kann die durch den digitalen Zugang erreichte Verfremdung helfen, die notwendige Distanz zu generieren, um den Text so kritisch und so objektiv wie möglich zu untersuchen. Die besondere Relevanz des sprachreflexiven Unterrichts wird auch von Budde betont (Budde, 2011), da dieser Auswirkungen auf alle anderen Teilbereiche des Sprachunterrichts (Sprechen, Zuhören, Schreiben, Lesen) hat (ebd.) und in diesem Szenario durch eine fachliche und technische Aufarbeitung des POS-Taggers gefördert werden kann.
Tatsächlich ist hier ein individueller Zugang zu unterschiedlichen sprachlichen Ebenen möglich, so kann von der Wortartenbenennung leicht auf die Satzebene gewechselt werden – und von dort auf z.B. eine manuelle Annotation stilistischer Mittel. Denn auch wenn die einzelnen Gegenstandsfelder des Sprachunterrichts zunächst separiert werden, um die Wissensvermittlung kleinteilig und organisiert anzugehen, so ist doch das Ziel im integrativen Unterricht, „Querverbindungen und Verknüpfungen zwischen den Bereichen zu schaffen und zu nutzen.“ (Budde, 2011, S. 43)
Der computerphilologische Zugang ermöglicht bei der Arbeit mit dem Tag-Struktur-Baum mehr als nur eine elektronische Variante der Fingerübung. Sowohl beim manuellen Taggen als auch beim automatisierten Taggen können die Lernenden Einfluss auf die Token-Benennung nehmen und eigenständig das theoretische Wissen nutzen, um individuelle Annotationsschemata zu entwickeln, die über die Wortarten-Annotation weit hinausgehen können. Dabei ist eine stark individuelle Herangehensweise von Vorteil, da die Lernenden bzw. die Lehrpersonen zunächst selbst entscheiden können, wie die Struktur aufgebaut sein soll. Des Weiteren profitiert der Unterricht von der Notwendigkeit, theoretisches Vorwissen zu reflektieren, um erstens Lücken aufzudecken und zweitens das Gelernte von „trägem Wissen“ (Budde, 2011) in anwendbares Wissen umzuwandeln und für den digitalen Einsatz aufzubereiten. Die selbstständige Strukturierung der Tags sowie der Austausch innerhalb der Arbeitsgruppe schulen die entsprechenden sozialen und metasprachlichen Kompetenzen. Dabei wird der Selbstbestimmungstheorie von Deci und Ryan (1994) entsprochen, wenn die Lernenden sich ihres eigenen Wissens bewusst werden und als kompetente Personen autonom an die Aufgabe herangehen können. Auch die soziale Einbettung des Lernprozesses ist durch den authentischen Austausch mit den Mitschüler*innen gegeben, was der Lernmotivation nachweislich zuträglich ist (Deci & Ryan, 1994).
Die Digital Humanities sind zuallererst in den Geisteswissenschaften beheimatet, aber deren Herausforderungen erfordern die Anwendung technischer Mittel. Daraus didaktische Anwendungen zu generieren, ist in vielerlei Hinsicht gewinnbringend. So fragt auch Busse „Wie können Hochschul-Studierende nichttechnischer Fächer im Rahmen ihrer disziplinären Hochschulausbildung praxisrelevant an bildungstheoretisch wertvolle informatische Inhalte herangeführt werden?“ (Busse, 2002, S. 132) – Eine Antwort darauf können die digital-geisteswissenschaftlichen Szenarien bieten, da sie informatische Zugänge zu nichttechnischen Themen (sowie geisteswissenschaftliche Zugänge zu informatischen Themen) nutzen, ausbauen und reflektieren.
McPherson betont, dass durch den Trend des ‚distance learning‘ in den 90er Jahren die digitale Herangehensweise der DH zunächst auf die reine Produktion von digitalen Lehrinhalten für die universitäre Lehre reduziert wurde und gar zur e-Learning Hilfswissenschaft degradiert wurde (McPherson, 2009). Das DFd-Projekt möchte jedoch die bestehenden fachdidaktischen Konzepte analysieren und auf Potentiale für Weiter- oder Neuentwicklungen untersuchen. Dadurch sollen den Lernenden bereits in der Schule und in der akademischen Lehre erste deutliche Schritte in Richtung Forschung und Forschungsinfrastruktur aufgezeigt werden. Daher benötigen die Digital Humanities Konzepte, um das Forschen selbst sowie den Umgang mit fachlichem Wissen und den entsprechenden Tools zu vermitteln. Hier bieten sich unter anderem reduzierte Anwendungen an, die jedoch die Frage aufwerfen, an welchem Ende eine Reduktion sinnvoll angesetzt werden kann. Sollte also eher die technologisch-methodische Komplexität herabgesetzt werden oder die fachliche Tiefe? Die Zielgruppe der aktuellen Tools der DH sind derzeit (Nachwuchs-)Wissenschaftler*innen, die je nach Anwendung eine Vielzahl an Parametern und Analysemöglichkeiten schätzen. Für Lernende, insbesondere auch fachliche Neu- und Quereinsteiger*innen, kann die Komplexität auf technischer und fachlicher Ebene hingegen rasch zu einem Hindernis werden.
Eine (weitere) Herausforderung der didaktischen DH-Konzepte stellt die Zielgruppe, genauer gesagt deren Heterogenität, dar. Die klassische Adressatengruppe als solches, nämlich Studierende reiner DH-Studiengänge, gibt es erst seit einigen Jahren, dazugerechnet werden müssen (da häufig die DH-Orientierung erst im Laufe der akademischen Karriere erfolgt) Geisteswissenschaftler*innen unterschiedlicher Fachrichtungen ohne technisches Hintergrundwissen. Noch dazu ist das akademische Karrierelevel (Student*in, Doktorand*in, Postdoc) sehr unterschiedlich. Geeignete Konzepte müssen sich also auf verschiedene (wissenschaftliche) Zielgruppen anpassen lassen. Zudem müssen flexible Lösungen für das Lehramt gefunden werden, damit Lehramtsstudierende im Schulunterricht die Herangehensweisen sinnvoll in die (digitalen und fachlichen) Vorkenntnisse ihrer Schüler*innen einfügen können.
Digital-philologische Tools eignen sich, aufgrund der ursprünglichen Intention ihrer Entwickler, vielseitige Forschungsfragen beantworten zu können, für interdisziplinäre – aber auch fachlich themenübergreifende Lehrsituationen (wie beispielsweise der Übergang von literatur- zu sprachdidaktischen Szenarien). Der technische Aspekt, der durchaus auch ein Gegenstand der wissenschaftlichen Forschungsarbeit darstellt, kann dabei über den medialen Übergang von Papier zu Maschine hinaus Perspektiven bieten.
Die Befürchtung, die oftmals den Digital Humanities entgegengebracht wird, dass Analysen das qualitative Arbeiten zugunsten quantitativer Verfahren vernachlässigbar machen, wird sich auch im Lehrkontext nicht bestätigen. Im Gegenteil: Eine Visualisierung von Analyseergebnissen, ohne den Text zuvor gelesen zu haben, kann zu allerhand irreführender, aus der Visualisierung fälschlich interpretierter Handlungsstränge führen, wie dies im entsprechenden Beispiel aufgezeigt wurde. Mittels der digitalen Anwendung wird die Wichtigkeit des qualitativen Arbeitens sogar betont, denn quantitative Visualisierungen in den korrekten theoretischen Kontext zu setzen, und mit dem vorhandenen theoretischen Vorwissen zu verknüpfen, bedarf einer soliden Textkenntnis und fundierten Gattungswissens. Die DH-Tools können neue Perspektiven des Textzugangs und zugleich die Grenzen digitaler Werkzeuge aufzeigen. Das Wissen kann somit in einem weiteren Schritt allgemein auf das breite Feld der Daten- und Informationsverarbeitung und die allgemeine Funktionsweise von Software und maschineller Sprach- und Textverarbeitung übertragen werden.
Budde, M.; Riegler, S.; Wiprächtiger-Geppert, M.: Sprachdidaktik. Akademie Verlag, Berlin, 2011.
Busse, J.: Informatik-Didaktik außerhalb der Informatik. DDI, 2002, pp. 131-139.
Bußmann, H.: Lexikon der Sprachwissenschaft. Kröner, Stuttgart, 2008.
Deci, E. L.; Ryan, R. M.: Promoting self-determined education. In: Scandinavian journal of educational research, 38(1), 1994, pp. 3-14.
Feierabend, S.; Plankenhorn, T.; Rathgeb, T.: JIM 2015. Jugend, Information, (Multi-)Media. Medienpädagogischer Forschungsverbund Südwest (mpfs), Stuttgart, 2015. Verfügbar unter https://www.mpfs.de/fileadmin/files/Studien/JIM/2015/JIM_Studie_2015.pdf (last check 2018-01-09)
Habermann, M.: Die Rolle der Digitalisierung im Fach ‚Germanistische Linguistik‘. Symposium Digitalität und Geisteswissenschaften. 2016. https://digigeist.hypotheses.org/author/meha (last check 2018-01-09)
Hessisches Kultusministerium (Hrsg.): Lehrplan Informatik: Gymnasialer Bildungsgang. Gymnasiale Oberstufe. 2010. https://kultusministerium.hessen.de/schulsystem/bildungsstandards-kerncurricula-und-lehrplaene/lehrplaene/gymnasiale-oberstufe (last check 2018-01-09)
Hessisches Kultusministerium: Lehrplan Deutsch: Gymnasialer Bildungsgang. Gymnasiale Oberstufe. 2010 https://kultusministerium.hessen.de/sites/default/files/media/go-deutsch.pdf (last check 2018-01-09)
Köhnen, R. (Hrsg.): Einführung in die Deutschdidaktik. J.B. Metzler, Stuttgart und Weimar, 2011.
Leubner, M.; Saupe, A.; Richter, M.: Literaturdidaktik. Akademie-Verlag, Berlin, 2010.
Mayring, P.: Combination and Integration of Qualitative and Quantitative Analysis. In: Forum Qualitative Sozialforschung, 2 (1), 2001. http://www.qualitative-research.net/index.php/fqs/article/view/967/2110 (last check 2018-01-09)
McPherson, T.: Introduction: Media Studies and the Digital Humanities. In: Cinema Journal, 48 (2), 2009, pp. 119-123. Verfügbar unter http://www.jstor.org/stable/20484452 (last check 2018-01-09)
Müller, S.: Digitalität in der mediävistischen Forschung. Symposium Digitalität und Geisteswissenschaften. 2016. https://digigeist.hypotheses.org/author/stmu (last check 2018-01-09)
O’Donnell, M.: UAM Corpus Tool. 2016. http://www.corpustool.com (last check 2018-01-09)
Rapp, A.: Manuelle und automatische Annotationen. In: Jannidis, F.; Kohle, H. & Rehbein, M. (Hrsg). Digital Humanities. Eine Einführung. pp. 15-18. J.B. Metzler, Stuttgart, 2017.
Sinclair, S.; Rockwell, G.: Voyant Tools. 2016. https://voyant-tools.org/ (last check 2018-01-09)
Schröter, J.: Digitalität und die Medienwissenschaft. Symposium Digitalität und Geisteswissenschaften. 2016. https://digigeist.hypotheses.org/86 (last check 2018-01-09)
Thaller, M.: Digital Humanities als Wissenschaft. In: Jannidis, F.; Kohle, H.; Rehbein, M. (Hrsg.): Digital Humanities. Eine Einführung. pp. 15-18. J.B. Metzler, Stuttgart, 2017.