From Diversity to adaptive Personalization: The Next Generation Learning Management System as Adaptive Learning Environment
urn:nbn:de:0009-5-52421
Abstract
Learning Management Systems (LMS), as the most widely used online learning systems in formal education, confront all learners with the same learning environment, although the learning-relevant characteristics of the learner are by no means homogeneous. In this article, we highlight ways in which LMSs, by linking institutional data sources and analytics tools, can provide personalized learning environments that adaptivly adjust to learners' needs and learning progress. In future adaptive personalized learning environments, the LMS as we know it today will merely be a building block within an open, modular, and distributed system architecture. We propose a five layer architecture that fits into the existing IT landscape of educational institutions and enables the coexistence of different components and paths for processing, storing, and analyzing data for the adaptation of personalized learning environments. The components in each layers can be complemented or replaced by other systems and services as long as the interfaces of the neighboring layers can still be served. This allows not only a step-by-step construction of a complex system landscape, but also a distribution of the computing load and multiple use of resources and services.
Keywords: e-learning; LMS, Learning Management Systems, Adaptive Systems, Personalized Learning, Adaptive Personalized Learning Environments
Common LMSs confront all learners with the same learning environment, although their learning-relevant characteristics are by no means homogeneous. Thus, learners are treated largely the same in terms of learning materials, instruction, review options, etc., despite differences in educational background, professional experience, personal competencies, needs, etc. The diversity of learners is in contradiction to a uniform learning environment, since different preferences and different needs in the course of learning may require an adaptation of the learning environment in terms of learning materials, instructions, feedback and forms of interaction.
An established approach for taking learning-relevant diversity characteristics into account is the personalization of learning environments as well as the continuous adaptation of the personalized learning environment. In this paper we show a way how established LMSs within an IT ecosystem of a university can become part of the architecture of an adaptive personalized learning environment. This architecture forms the basis for a next-generation LMS because it incorporates diversity characteristics of learners from all available data sources, continuously determines and updates them using learning analytics methods, and exploits these characteristics to adapt the personalized learning environment for each learner. The special feature of the five-layer architecture presented here is that the components in each layer can be complemented or replaced by other systems and services as long as the interfaces of the neighboring layers can still be served. This open, modular architecture allows not only a step-by-step construction of a complex system landscape, but also a distribution of the computing load and multiple use of resources and computing services.
To this end, we first examine the concept of diversity and consider different dimensions of diversity characteristics and their impact on learning. We then describe the gradual transition from today's LMS to personalized and finally to adaptive personalized learning environments.
Using two exemplary use cases in section 2, we describe concrete learning situations in which the learning environment reacts adaptively to the characteristics and behavior of the learners. For each use case, we also explain the technical requirements such as the required data, necessary processing steps and adaptation procedures. In Section 4, we present the reference architecture of a Next Generation LMS that provides adaptively personalized learning environments to each learner. The characteristic of this architecture is the processing of a variety of different data sources, persisted in models and databases, and used with data analytics to generate adaptive personalized learning environments. The article concludes in section 5 with a conclusion and outlook.
In the OECD countries, the proportion of young people between 25 and 34 years of age with a university degree rose by a total of 14 percentage points between 2000 and 2013 (OECD, 2020). As one measure to increase number of students, universities have opened up to 'non-traditional students'. The term 'non-traditional students' refers to the socio-demographic diversity of learners compared to traditional participants in higher education (Chung et al., 2014). However, there are different views on the characteristics that can be used to identify 'non-traditional students'. Chung et al. (2014) identified 13 categories of socio-demographic characteristics in a literature study. One part of these categories are based on the person (age, sex, ethnicity), the state of health (disability or trauma), the current living situation (multiple roles) and other sociological factors (being disadvantaged, demographically different from norm). The other part of catagories point out differences in the admission pathway and in the course of study (mode of study, gap in studies, enrolment in non-traditional programs, previous degree, commuter status).
Diversity is equally evident in learners' learning-related abilities and characteristics such as self-efficacy (Menold and Jablokow, 2019; De Clercq et al., 2020; Pluut and Curşeu, 2013), cognitive style diversity (Menold and Jablokow, 2019), learning styles, lexical density and lexical diversity (Gregori-Signes and Clavel-Arroitia, 2015) as well as the digital skills (Hatlevik et al., 2015). These learning-related abilities and characteristics may in turn be determined by sociodemographic characteristics that indicate social milieus. In this context, Bremer (2004) points out, for example, that the ability for self-regulated learning is shaped by the social milieu.
A comprehensive body of empirical work demonstrates that diversity has an impact on learning behavior and thus on learning outcome. For instance, De Clercq et al. (2020) were able to attribute performance differences in the first year of study to differences in the high school grade, socioeconomic status, informed-choice, and self-efficacy beliefs. With regard to collaborative learning, Pluut and Curşeu (2013) showed the influence of gender, nationality, and life experience within a group on the performance in creativity tasks.
The influence and impact of diversity on learning can be substantiated not only empirically, but also theoretically. According to the situated learning theory (Lave and Wenger, 1991) it can be argued that a fit of learning material (e.g. case studies) to a learner's experiential background can increase learning success. A discrepancy between relevant learner characteristics and the design of the learning environment can therefore be detrimental to learning.
From the perspective of teachers, this raises the question of how diversity characteristics can be taken into account in teaching. General recommendation like the use of multicultural language in online courses (Good et al., 2020) or the use of gender-appropriate teaching, contents, or language aims at a uniform implementation for all learners. In most cases, however, teachers are unaware of the diversity characteristics of their students, both individually and aggregated across a cohort of students. This is due to a variety of reasons. First, there is a consensus that individual learners should not be disadvantaged or advantaged on the basis of certain characteristics. It is therefore forbidden, for example, to gather information about socio-economic status or ethnic origin and to derive immediate didactic actions from this. These ethnic and moral boundaries are therefore regulated in laws against discrimination, but also prohibited through laws like the GDPR (European Commission, 2016). Second, there are characteristics such as learning style or self-efficacy, which the learners themselves are often not aware of and which can only be determined using standardized survey instruments.
On the other hand, educational institutions collect a necessary set of sociodemographic characteristics when a student enrolls to a study program (e.g. date of birth, gender, address). Information about the course of study (e.g. prior knowledge from past courses) is available from university IT systems. Both information sources are not available to lecturers. The learning behavior within online learning environments, including LMS, is mostly captured in detailed log files, but is only made accessible to a limited extent using learning Analytics methods like dashboards (cf. Schwendimann et al. (2016)). Learning-related characteristics or interactions are more likely to be grasped accidentally by teachers, for example in conversations (e.g. lexic diversity) or by assessing learning performance.
This creates a dilemma. On the one hand, teachers are confronted with an increasingly diverse student body and have to deal with it. On the other hand, they are only able to grasp learning-related diversity characteristics to a very limited extent and thus cannot take them into account in the design and implementation of learning opportunities. Since many educational institutions have intensified online learning in the context of the COVID-19 pandemic, diversity characteristics need to be considered in blended and online learning, too.
LMS as a prominent representative of online learning environments should support teachers in recognizing diversity and incorporating it into online learning experience. However, in a typical LMS like Moodle, Ilias, Canvas or Blackboard (Ifenthaler, 2012) all learners of a course are usually confronted with the same learning environment, although their learning characteristics and learning interactions are by no means homogeneous. Thus, learners are largely treated the same in terms of learning materials, instructions, assessment options, etc., despite differences in educational background, work experience, personal skills, needs, etc. The diversity of learners is in contradiction to a uniform learning environment, since different preferences and, in the course of learning, different needs may require adaptation of the learning environment in terms of learning materials, instructions, feedback and forms of interaction.
A promising solution here is to personalize the learning environment so that each learner gets a suitable learning environment. Current approaches to personalizing learning environments often use a one-time cofinguration of the learning environment at the beginning, which depends on an analysis of the parameters relevant for the configuration. For this purpose, e.g. questionnaires, diagnostic tests, or data from previous courses can be used to determine the parameter values for each learner. Such a configuration makes it easier for learners to access information, as only the relevant ones are displayed. For example, only the information of the exercise groups to which a learner is assigned is displayed.
Or the material and tasks from knowledge areas in which a learner did not achieve good results in the entrance test are recommended. However, this kind of personalization through initial configuration does not support adaptation to learners' changing needs in shorter periods of time, which may result, for example, from a current drop in motivation, an accumulation of missed deadlines, or sudden problems in a learning group.
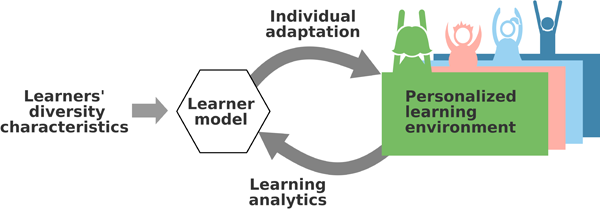
Figure 1: Cycle of a diversity-related personalized learning environment that is individually adapted through learning analytics
In such a situation, the goal is to dynamically personalize the learning environment to provide personalized learning support that adapts to learners' current needs. For this purpose, the relevant characteristics, which may vary in the entirety of the learners, are mapped for each learner onto an individual learner model (see Figure 1). On the basis of the current characteristics of the learner model, the personalized learning environment is created or, if necessary, adapted in the event of changes. The learning behavior can change with respect to different characteristics on different time scales. Examples are deviations of the current behavior from a previous work plan, errors in self-testing and exercises, etc. Such feature changes can be captured with learning analytics approaches and lead to an update of the respective learner model: an adaptation loop is created. Because it cannot be assumed that ex-ante appropriate adaptations of the learning environment for all occurring behaviors can be defined, a machine learning approach that can determine the appropriate personalization for the learner in each case based on student data (diversity characteristics, interactions, learning goal achievements) and data about learning opportunities (programs, courses, learning activities) seems necessary.
With the help of such an approach, the implementation of a personalized adaptive learning environment becomes achievable, which provides personalized dashboards, learning materials, interaction opportunities, and support based on a dynamic learner model and tutoring model according to the learner's needs.
A good overview of the current state of research and the different approaches to design and implement adaptive personalized learning environments can be derieved from systematic reviews of literature (Vandewaetere et al., 2011; Grubišić et al., 2015; Xie et al., 2019; Talaghzi et al., 2020; Martin et al., 2020) and systems (Newman et al., 2016; Osadcha et al., 2020). In addition, systematic literature reviews can be found on specific aspects of adaptive learning environments such as the learning style (Akbulut and Cardak, 2012; Kumar et al., 2017) and the user model (Nakic et al., 2015). Grubišić et al. (2015) specifically addresses the requirements for adaptive courseware. Only a few reviews examined the adaptation methods used (Vandewaetere et al., 2011; Talaghzi et al., 2020), while the system architectures within the educational institutions were not included in any of the mentioned survey papers. In the following section we will exemplify two use cases to outline the future of LMSs as one building block in a broader institutional environment of heterogeneous systems and data sources.
In this section, we present two exemplary use cases to illustrate adaptive personalization in a digital learning environment. We describe concrete learning situations in which the learning environment reacts adaptively to the characteristics and behavior of the learners. For each use case, we explain the technical requirements such as the required data, necessary processing steps and adaptation procedures.
The first use case shows how to consider diversity characteristics such as prior knowledge, professional experience and learning progress when providing personalized learning material (see Figure 2). The provision of such an adaptive personalized learning environment requires the LMS to select appropriate learning resources from a database of all learning resources for a given course. Therefore, the LMS maintains a pool of learning resources, such as slides, course texts, tests, videos, book chapters, with associated metadata.
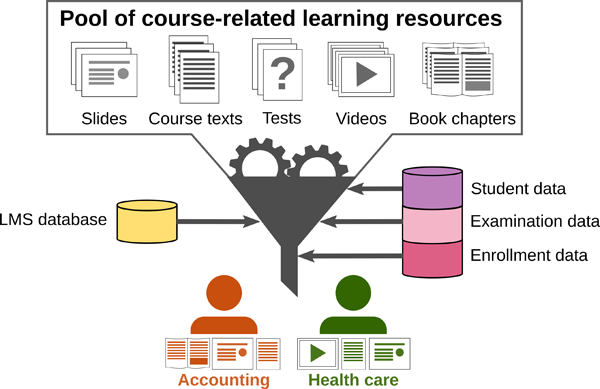
Figure 2: Selecting learning resources and assessments considering a learner model including behavioral data from the LMS as well as enrollment and examination data from other sources.
In order to adaptively personalize the learner's learning environment according to diversity characteristics, the LMS needs to know the respective characteristics of a given learner. For this purpose, the adaptive personalization functionality of the LMS uses data about the learner available from data sources existing in the IT environment of the educational institution (e.g. data about enrollments, examinations, course selections) and interaction in the LMS to construct a learner model for each learner. For example, enrollment data can be used to determine the professional background of a learner (e.g. completed courses of study or vocational training), while data about finished courses and exams may be used to assess prior knowledge, and interaction and test data of an LMS may be used to measure learning progress.
This learner model reflects the learner's diversity characteristics, and is used to create a learning environment suitable to the current needs of the learner. For example, a learner with a professional background in business administration is provided, if available, with case studies and exercises in the business administration domain while another learner with a background in the health care domain may be provided with case studies and exercises in the health care domain. The learner model enables the adaptive LMS to assess prior knowledge on given concepts or competences based on prior course selection, exams and assignment results. If sufficient prior knowledge exists, the learning environment may offer short summaries including references to background material instead of the usual comprehensive course material and exercises. If tests show deficits, additional hints, learning material and tests may be offered, so that the learner may close knowledge gaps. In this way, a simple form of digital learning support may be implemented.
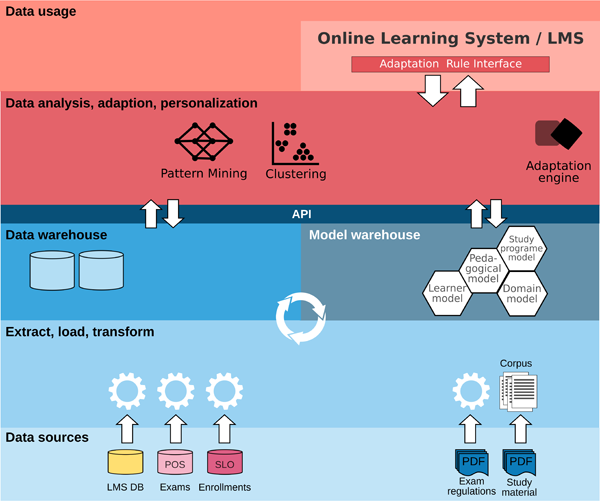
Figure 3: Adaptive LMS architecture for use case 1
In principle, a platform for implementing such adaptive personalized learning environments needs to support the following steps in the adaptation cycle (see Figure 3):
-
Connection to data sources: relevant data from data sources existing in the educational institution must be imported. Examples include study program enrollment data, examination data, course enrollment data, personal learning environments in existing LMS, study program related information in textual form, such as learning material or exam regulations, or represented by metadata (for other media).
-
Data extraction, loading and transformation: transforming heterogeneous data sources into a format that allows structured processing. Examples include conversion of textual learning material into a corpus, which can be used to identify semantic similarities or references between courses or learning material.
-
Provision of data and models: a data warehouse approach is used to enable reuse of transformed data for new kinds of analyses, while semantic processing of data requires creation and maintenance of semantic models such as learner model, pedagogical model, study program model, and domain models. The reader should note that whenever data is changed (whether due to changes in the data sources or in the semantic models) the data and model warehouses needs to be kept consistent. This is indicated by the circle of arrows in the middle of Figure 3.
-
Provision of data analysis, adaptation and personalization: data analysis services such as cluster analysis or association mining support assessment of the impact of adaptation and personalization actions as well as identification of new potentially useful personalization rules. A personalization rule defines a condition-action pair: when the condition, which is based on models, is fulfilled, the action specifying modifications of the learning environment should be executed. Such personalization rules are used by an adaptation engine to adapt the content and functionality of the learning environment using the Adaptation Rule Interface (ARI).
-
Data usage: as a result of the previous steps, data is used by the respective online learning system to present (a part of) the personalized learning environment. Every participating LMS or learning tool must provide an implementation of the ARI that can be used by the adaptation engine to dynamically adjust the content and functionality of the personalized learning environment. Interaction of the learner with the learning environment will subsequently be captured and lead to changes in the respective data sources (e.g. LMS logs or state) and models (e.g. learner model), thus potentially triggering personalization rules leading to another adaptation. In this way, the adaptive personalized learning environment is constantly adapting to the needs of the learner.
In the literature, many approaches to support online adaptive learning have been described (cf. Talaghzi et al. (2020)). While previous work focuses on providing specific adaptation features regarding content or assessments, our approach addresses the needs, firstly, to embedd such support in an existing IT infratsructure, and secondly, to support an ongoing adaptation loop that allows continuous learning of adaptation rules (i.e., learning on the meta level: learning how to better adapt). The proposed architecture thus provides a framework for integrating other, more specific adaptation approaches and is open to make such adaptation rules available for new LMSs or learning tools, if they provide the required interfaces.
In the second use case we are looking at the participation of group members in a web conference while working on a joint solution in a shared editor, which is a component of the LMS. As shown in Figure 4, three students are jointly solving a problem that was outlined in a LMS course. In parallel, they discuss their work by means of a web conferencing system extending the LMS. The task requires active and lively collaboration from all group members, including joint writing. This collaboration is essential for a successful solution of the task because it requires the integration of different perspectives. Figure 4 shows that two of the group members (shown at the bottom of the screen) work very well and closely together. The third member (shown on the top left of the screen) does not participate well, does not communicate suitably for an efficient group learning - indicated by the distance from the other members - and appears dissatisfied e.g. with his position in the group or with the other group members - indicated by his negative facial expression. His position in the group might lead to poor participation at solving the problem. The person may be excluded from discussion and will not be able to contribute to the group's solution. Consequently, he will not benefit from the learning process as the other group members do.
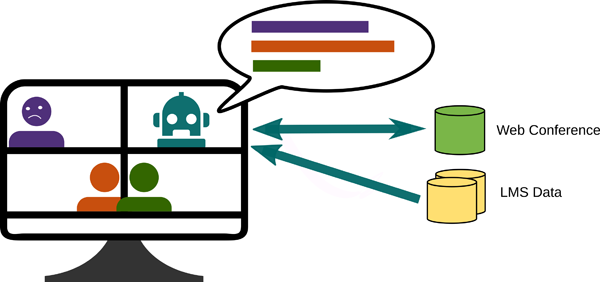
Figure 4: Participation support in an online conference
In this use case, the collaboration in the learning group is supported by an Educational Chatbot (cf. Perez et al. (2020)). This bot perceives and analyses the described problems in collaboration and communication of the group. Among other things, it considers the diversity characteristics of communication behaviour, emotions, and learning progress. To do this, it not only uses data captured by the web conference system, but also data from the LMS such as individual text contributions and writing progress in the shared editor. The analysis leads to personalised provision of feedback for the group discussion. The Educational Bot takes into account the individual contributions to the conversation (e.g. the number of words), the emotions from voice sentiment analysis, or lexical analysis in order to relate the terms used with the learning resources in the LMS. It then “takes the floor" and thus addresses all group members. It gives them advice on communication, collaboration, and coordination. In this way, it raises group members' awareness and contributes to the recognition and elimination of problems regarding the group process. Its feedback ensures that all group members participate successfully in the learning process. Figure 5 shows in detail the technical architecture behind the use case.
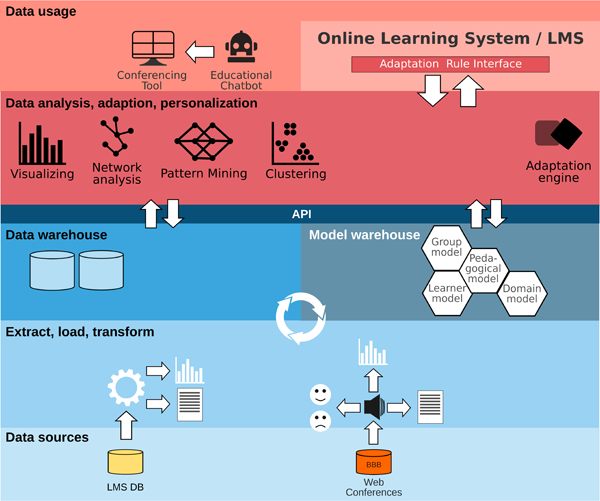
Figure 5: Architecture Use Case 2
In order to generate appropriate feedbacks, existing data is taken from both, the LMS and the web conference system. This is followed by data preparation, in which heterogeneous data is converted into a suitable format that allows automatic further processing by the system. Specific properties are extracted from the LMS data for later statistical analysis and suitably processed – symbolised by a histogram in the left side of the figure. These include, among other things, the time each member speaks and the interconnectedness, i.e. who communicates with whom. The text resulting from the captured audio conversations of the group members are converted into a format that can be interpreted by the system using Natural Language Processing (NLP) methods - symbolised by a text page.
The sentences spoken in the web conference are first transcribed from the audio format into a text format. They are then subjected to the same steps as described by the processing of the LMS data (see above). In addition, a possible basic emotional attitude of group members is inferred from the voice pitch and possibly the analysis of the facial expressions using computer vision algorithms. This is symbolised in figure 5 by the two emoticons.
In the next layer - analoguous to the description of use case 1 - the data provision in form of a data warehouse and the semantic modelling takes place. The model wharehouse includes the following model types: group model, learner model, pedagogical model and the domain model. The latter three models are discussed in section 3.1.3. The group model represents and characterises the group as a whole and offers information related to pedagogical and social aspects and is formed from the individual student models (e.g. Jaques et al. (2002); Vizcaíno et al. (2000)). It takes into account, e.g., degree and type of participation, abilities, type of prefered exercises, motivation, made mistakes of the group members.
The transition from the data preparation layer ("extract, load, transform") to the data provision and model building layers ("data warehouse and model warehouse") is performed continuously during the group's use of the system. Whenever data or models change due to group members' interactions consistency must be maintained by updating dependent data or models.
The services of the data warehouse and model warehouse are made available to the LMS via an Application Programming Interface. Similar to use case 1, in the next layer the adaptation engine uses the models provided by the model warehouse and, if necessary, an adaptation engine adapts the personalized LMS. Data analysis techniques, e.g. clustering and association mining, enable the evaluation and learning of new personalisation rules. In this use case, techniques for SNA are added.
The upmost Data Usage Layer representing the Online Learning System uses the services of the data analysis, adaption and personalization layer via the ARI. The Data Usage Layer includes the conferencing tool and Educational Bot, both connected to the LMS.
The architecture described (see Figure 5) enables the Educational Bot to provide the above mentioned personalized feedback to all group members on communication, collaboration, and coordination. Thus, it supports the awareness of the group members and helps to address problems regarding the group process.
In contrast to support of group participation, Kim et al. (2020) developed a chatbot agent that monitors and promotes discussions among group members. The bot fullfills the task of moderating the group less as a tool, more as an acting member. To do this, it monitors the participation of the members and, if necessary, encourages them to contribute to the discussion, reminds them of the remaining time and promotes the exchange of diverse opinions. Trausan-Matu (2010) deals with the analysis of conversations of students in an online messenger in a CSCL context. NLP and social network analysis (SNA) are used to analyze chat histories for tutors and to create interactive graphs to help them evaluate and assess the collaboration. Ferguson et al. (2013) uses a combination of natural language processing techniques and machine learning methods to develop a self-learning framework that identifies exploratory learning dialogues based on synchronous text chats. It was tested using a two-day online conference.
The previous section has shown how the five-layer architecture can be used to implement the two use cases. From these concrete examples, a more generic architecture with its components and their interaction will be elaborated and described in the following before emphasizing specific requirements for adaptive personalized learning environments.
In Figure 6 a layered architecture of an adaptive personalized learning environment is shown. This architecture is based on access to various data sources in the bottom layer. Such data is preprocessed in the layer above (extract, load, transform (ELT) layer) and persisted in a data warehouse or model warehouse in the third layer for further use. These three lower layers are independent of a specific application and form the basis of adaptation and personalization of a learning environment consisting of different tools, applications and LMS. The two layers on top of it can access the data in the data warehouse via an API to first perform analysis or determine adaptations before the data usage layer finally provides the adaptive personalized learning environments that can be used by learners and teachers.
The LMS plays an important role in this architecture, but not necessarily a central one. LMSs are just one representative of online learning systems that, among other learning and teaching related applications, are available for the stakeholders involved. However, an LMS is not understood as an atomic entity, but as a modular, distributed, and extensible system. For example, the database of an LMS is separated from the actual application program and the LMS extensions (cf. plugins) are interchangable. The processing steps in the upper two layers can be implemented as part of the LMS or in separate service. While current LMS are focused on content delivery and organizing learning in a static way, they are now considered both, a source of interaction data to be used for analytics and adaptations, and a receiver of adaptation requests regarding content, user interface and possible interactions for a specific learner or learning group. The LMSs of today are not obsolete, as long as they provide the necessary interfaces and thus pave the way for iterative further developments. This is the case with LMS like Moodle, Ilias, and StudIP. In the following subsections, the five layers of architecture corresponding to Figure 6 are explained from bottom to top.
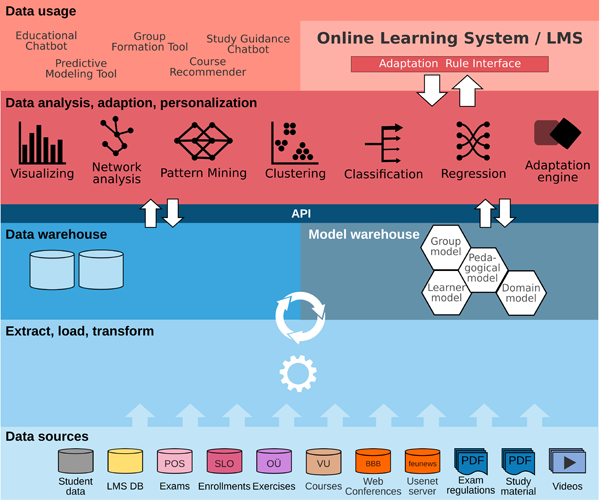
Figure 6: Principle architecture supporting adaptive personalized learning in LMS and other online learning systems
In the IT ecosystem of an educational institution, various systems where information about students and their diversity characteristics, learning activities, study histories, and public or group-public interactions are stored, can be found. In this case an LMS's database is also considered as a data source separate from the application program. Collections of learning resources such as textbooks, videos, and audio are data sources as well. Instructors and students are often unaware of the scope, content, and relationships of these data source. In addition, IT professionals and administrators in charge of these systems are often unaware of the potential uses that such data offers for learners and educators. Therefore, questions about the nature, scope, and quality of the data must be answered first. Then, selected features of relevant data sources can be made available for subsequent processing steps in the ELT layer using data interfaces (e.g., REST, SOAP) to be requested periodically or at real time. The example in Figure 6 shows at the bottom a set of administrative systems that are available at the largest distance learning university in Germany, and which are useful in the use cases described previously.
The required data sources are available for retrieval via various programming interfaces. The structure of the data must be aligned and unified during preprocessing. Data containing common keys such as the matriculation number in examination data and course enrollments must be linked for further processing. If the data is unstructured or has little structure, the required information must be extracted, analyzed and compiled. In Figure 6, this concerns for example the creation of a corpus of study materials (Seidel et al., 2020) and the analysis of image, audio and text information from learning videos. No matter what type of data is involved, it must be prepared in such a way that it can be persisted in the subsequent upper layer.
The data resulting from the ELT layer is persisted into suitable databases or data representations or fed into models. The models can represent very different learning-related and teaching-related aspects. Essential is a learner model (cf. Nakic et al. (2015)), which includes demographic and functional diversity characteristics of each learner. In pedagogical models, learning goals, didactic actions, prior knowledge and learning styles of individuals and groups are mapped. Domain models describe knowledge about subject-related learning content (cf. Sarwar et al. (2019)). In collaborative learning settings, group models can help to represent processes and characteristics of the group as a whole as well as the relationships between the individual group members.
While the layers described so far were independent of concrete online learning systems or other learning applications, this layer contains data processing procedures that are intended for an application or a group of applications aiming at supporting a specific learning process. The data processing concerns on the one hand data analysis with the help of learning analytics and data mining methods (e.g. visualization, SNA, frequent pattern mining, clustering, classification, regression). Results from the utilization of these methods can be used in the following upper layer (data usage) or modify and extend the models in the layer below. On the other hand, in this layer the computation of the personalizations and adaptations required for the individual learner is performed with the help of a so-called adaptation engine (Veiel et al., 2011; Veiel, 2013). The adaptation engine checks the fulfillment of previously defined or utomatically generated adaptation rules. In order to let rule execution have an impact on the personalized and adaptive learning environment, a connection to the ARI of the layer above is required.
In the application layer there are applications of different kinds (e.g. chatbots, recommender systems, online learning systems), which enable personalization and adaptation in different ways and therefore have to rely on the data in the previously described layers below. One of these applications is the classic LMS as an example of an online learning systems. However, the data storage of these applications takes place in the data source layer, so that, for instance, the log data generated in an LMS can be captured and used for analytics and adaptation as well.
Of special importance in this layer is an extension of Online Learning Systems, i.e. of LMSs and other learning applications, which provides an interface for the implementation of adaptations. We refer to this extension as the ARI. In practice, the ARI is used by the adaptation engine to perform adaptations according to the adaptation rules. It maps abstract adaptation actions defined in the rules on to specific application changes. Its main task is to allow the personalization of content, didactics or presentation visible to the learner in the user interface. For this purpose, specific methods of the learning environment (e.g. direct messages, system notifications), browser specific functions (e.g. alerts, browser-notifications) or specially implemented procedures (e.g. text highlighting, change of text order, modal dialogs, hyperlinks) can be used. In order to use these methods in a way that does not interrupt the user in the learning process, context information and also reactions to past adaptations have to be taken into account before an adaptation is made effective.
In order to implement such an architecture, not all components have to be realized from the beginning and not every layer has to be fully implemented. It makes sense to begin with vertical slices, in which, for example, the data of a source is preprocessed and made available for an immediate analysis within an application. Iteratively, data sources can be added, preprocessing can be automated, and analysis and adaptation methods for different applications can be improved and compared. Even if an implementation of the architecture starts small, it is important to keep from the beginning requirements in mind that are crucial for further expansion and scaling of the system.
The architecture already gives an impression of which components a next generation LMS requires and how they interact. However, this schematic view does not take into account some of the challenges that play a role in development, deployment, and also in long-term operation. Particularly noteworthy are the needs of teachers and learners, who so far have had very little experience with personalized learning offerings in general and adaptive systems in particular. In the following subsections, we will address technical requirements regarding the system architecture and the interaction of data sources, models, and applications as well as the requirements of teachers and learners regarding such learning environments.
Basically, an adaptive learning environment reacts to changes in the data relevant to the adaptation rules. Changes in data must be detected as soon as possible in order to update the learner model which in turn may trigger adaptations if the adaptation engine considers them as favorable in the user's current context of use. Thus, models that are based on current data must be updated immediately. If adaptation rules are seen as just another type of model, data analytics can be used to identfy new learning patterns and new adaptation rules potentially useful to learners with similar characteristics. In this way, new adaptation rules can be derived from the behavior of a user and applied immediately.
A new data source is created whenever a new application is added to the application layer and trace data of user interactions is created. New data sources can also result from the creation of interfaces to existing or newly introduced institutional IT systems. In this case an Enterprise Service Bus would be capable to connect multiple data providers and services (Kiy et al. (2014)). The requirement for extensibility with respect to additional and possibly improved models results from the potential inadequacies of the models used currently.
In regular operation, the question arises whether backward compatibility must be ensured if students want to access a course whose personanlization is not based on current data and models, but represents a previous state. It is expected to find a learning environment in the state in which one left it (years ago). A historical configuration of the system including the data, models and applications existing at a point in time in the past could be provided by version management of the relevant artifacts.
Scalability with respect to a large number of courses and learners implies a high volume of log data and learning outputs. The richer the communication medium, the more data is generated. In addition to periodically changing data that must be retrieved and pre-processed, for example, once a semester or once a day, continuously accumulating data like log data poses a particular challenge. Therefore, system architectures capable to process large amounts of data must not only be able to link and process data in batch processing, but must also be able to deal with continuous data streams from different sources.
In a learning application appropriate ways need to be found on how to enact personalizations in terms of awareness information, an offer for action, or a system-determined intervention. The urgency of an intervention can also be controlled by the choice of actuators. For example, a color highlighting of a particular learning object is less intrusive and disruptive than a modal dialog containing a hint. Contextual information must be taken into account by software sensors in order to initiate adaptation-related user actions at the right time and at the right place within the application. In order to be able to evaluate the success of a personalization or adaptation retrospectively, trace data must be recorded and taken into account for evaluating the suitability of upcomming adaptations.
All this requires that the target system can be extended through plugins or modified at its core. Visible adaptation targets such as awareness information, displaying a hint, personalized feedback, or modified controls must fit seamlessly into the user interface design, so that the user is not irritated by inconsistent design.
Teachers must be in control of the way adaptation takes place in their online teaching. Therefore, they must be enabled to shape the learning environment for their purposes. This includes not only the selection of appropriate adaptive applications according to their intended didactic design and target audience, but also the selection of appropriate models, model parameters and the necessary data sources. For example, in a freshmen course it makes little sense to consider the previous course of study when forming a group, while in a course for advanced students the knowledge from previous semesters may play a role. Consequently, the teacher would substitute all model parameters related to past semesters by others representing past learning behavior or demografic data.
The more an adaptive system influences the actions of learners, the more important it becomes to explain the process of decision making in a comprehensible way. In order to explain a model, it must be interpretable in some way. One way to achieve interpretability is to restrict the algorithms in use to a subset that produce interpretable models. Linear regression, logistic regression and the decision tree, for example, produce interpretable models. Other algorithms, however, can only be evaluated using model-specific or model-agnostic interpretive methods.
In this respect, data scientists need to comply with users data literacy competencies by providing good explainations about what data has led to a reaction of the system and what needs to changed to see another reaction. Due to the proposed Digital Services Act of the European Commission (European Commission, 2020), however, it can be assumed that recommender systems and thus also adaptive learning environments must explain the outcome of algorithm-based decisions to the users in a comprehensible way. It is no longer sufficient to explain basic procedures on a separate website (e.g. as part of a privacy policy). Explanations are required at the points where they influence the user's actions.
From here, it is a logical step to provide users with the means to exchange models or change, exclude or add model parameters to suit their needs. This would prevent incapacitation and enable student-centered learning in adaptive learning environments.
From the literature, we are aware of several diversity dimensions including their impact on learning. Thus, there is a chance to use the learning-relevant characteristics and behaviors in favor of the learners. In much the same way that teachers in the classroom adapt and respond to the needs and characteristics of their students, teachers in online teaching should be able to do the same. For larger numbers of students, this can only be accomplished with computer support and the use of (existing) data sources. Current LMSs fullfil the basic requirements for such support, but cannot personalize learning or adapt the personalization to changing needs and performance.
One approach would be to extend current LMS with specific adaptive personalization functionality. This would allow implementation of dedicated use cases. However, it would make reuse more difficult, further extensions more complex, and tie the institution to an ever-growing monolith that has to combine all possible functions and services required by students and teachers.
In our opinion, in future adaptive personalized learning environments, the LMS as we know it today will merely be a building block within an open, modular, and distributed system architecture. This architecture fits into the existing IT landscape of educational institutions and enables the coexistence of different components and paths for processing, storing, and analyzing data for the adaptation of personalized learning environments. The components on each of the five layers of the architecture can be complemented or replaced by other systems and services as long as the interfaces of the neighboring layers can still be served. For example, the preprocessing of video-based resources can be complemented by a Speech2Text component whose resulting transcripts are transformed into a text corpus in a similar way as text-based study materials (e.g., scripts, presentation slides). With the help of Knowledge Graphs or NLP systems, different methods can again be applied in the analysis layer to make use of the text copora. This open, modular system allows not only a step-by-ste dconstruction of a complex system landscape, but also a distribution of the computing load and multiple use of resources and computing services. Coexistence of components also refers to the presence of various data-using learning applications, which include LMSs as well as testing systems, tutoring systems, communication platforms, and web conferencing systems. The interaction of components at each of the five layers enables multiple varieties of personalized adaptive learning environments within and alongside existing LMSs. It all adds up to the next-generation LMS.
The question now is how to get from the current to the next generation of LMS. To answer this question, it is helpful to take a look at the current state of research in the field of adaptive learning. Many questions remain unanswered, and most approaches have only been evaluated under controlled conditions or over a short period of time. However, especially for the investigation of this field, the architecture described in this paper offers great potential, since it provides many different entry points for research and can be built up gradually. In the research cluster D²L² at the FernUniversität in Hagen, several projectsdare already pursuing this goal and approaching it from different disciplinary as well as technical directions.
Acknowledgements
This research was supported by the Research Cluster "Digitalization, Diversity and Lifelong Learning -– Consequences for Higher Education“ (D²L²) of the FernUniversität in Hagen, Germany.
Akbulut, Y.; Cardak, C. S.: Adaptive educational hypermedia accommodating learning styles: A content analysis of publications from 2000 to 2011. In: Computers & Education, 58(2), 2012, pp. 835–842. ISSN 0360-1315. doi: 10.1016/j.compedu.2011.10.008 https://www.sciencedirect.com/science/article/abs/pii/S0360131511002521?via%3Dihub (last check 25.03.2021)
Bremer, H.: Der Mythos vom autonom lernenden Subjekt. Zur sozialen Verortung aktueller Konzepte des Selbstlernens und zur Bildungspraxis unterschiedlicher sozialer Milieus. In: Engler, S.; Krais, B. (Ed.): Das kulturelle Kapital und die Macht der Klassenstrukturen. Sozialstrukturelle Verschiebungen und Wandlungsprozesse des Habitus. Juventa, Weinheim/München, 2004, pp. 189–213.
Chung, E.; Turnbull, D.; Chur-Hansen, A.: Who are ’non-traditional students’? A systematic review of published definitions in research on mental health of tertiary students. In: Educational Research and Reviews, 9(23), 2014, pp. 1224 – 1238.
De Clercq, M.; Galand, B.; Frenay, M.: One goal, different pathways: Capturing diversity in processes leading to first-year students’ achievement. In: Learning and Individual Differences, 81, 2020, pp. 101908. ISSN 1041-6080. doi: 10.1016/j.lindif.2020.101908. https://www.sciencedirect.com/science/article/abs/pii/S1041608020300881?via%3Dihub (last check 2021-03-25)
European Commission. Regulation (eu) 2016/679 of the european parliament and of the council of 27 april 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing directive 95/46/ec (general data protection regulation), 2016. URL http://data.europa.eu/eli/reg/2016/679/2016-05-04 . (last check 2021-03-25)
European Commission. Proposal for a REGULATION OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL on a Single Market For Dig- ital Services (Digital Services Act) and amending Directive 2000/31/EC COM/2020/825 final, 2020. URL https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52020PC0825 . (last check 2021-03-25)
Ferguson, R.; Wei, Z.; He, Y.; Buckingham Shum, S.: An evaluation of learning analytics to identify exploratory dialogue in online discussions. In: Proceedings of the Third International Conference on Learning Analytics and Knowledge, LAK ’13, New York, NY, USA, 2013, 85–93. Association for Computing Machinery. ISBN 9781450317856. doi: 10.1145/2460296.2460313. http://dl.acm.org/citation.cfm?doid=2460296.2460313 (last check 2021-03-25)
Good, J. J.; Bourne, K. A.; Drake, R. G: The impact of classroom diversity philosophies on the STEM performance of undergraduate students of color. In: Journal of Experimental Social Psychology, 91, 2020, pp. 104026. ISSN 0022-1031. doi: 10.1016/j.jesp.2020.104026. https://www.sciencedirect.com/science/article/pii/S0022103120303668?via%3Dihub (last check 2021-03-25)
Gregori-Signes, C.; Clavel-Arroitia, B.: Analysing Lexical Density and Lexical Diversity in University Students’ Written Discourse. In: Procedia - Social and Behavioral Sciences, 198, 2015, pp. 546–556. ISSN 1877-0428. doi: 10.1016/j.sbspro.2015.07.477. https://www.sciencedirect.com/science/article/pii/S187704281504478X?via%3Dihub (last check 2021-03-25)
Grubišić, A.; Stankov, S.; Žitko, B.: Adaptive courseware: A literature review. In: Journal of Universal Computer Science, 21(9), 2015, pp. 1168–1209. ISSN 09486968. doi: 10.3217/jucs-021-09-1168. http://www.jucs.org/doi?doi=10.3217/jucs-021-09-1168 (last check 2021-03-25)
Hatlevik, O. E., Guomundsdóttir, G. B.; Loi, M.: Digital diversity among upper secondary students: A multilevel analysis of the relationship between cultural capital, self-efficacy, strategic use of information and digital competence. In: Computers & Education, 81, 2015, pp. 345–353. ISSN 0360-1315. doi: 10.1016/j.compedu.2014.10.019. https://www.sciencedirect.com/science/article/abs/pii/S0360131514002395?via%3Dihub (last check 2021-03-25)
Ifenthaler, D.: Learning Management System. Springer US, Boston, MA, 2012, pp. 1925–1927. ISBN 978-1-4419-1428-6. doi: 10.1007/978-1-4419-1428-6. https://link.springer.com/referencework/10.1007%2F978-1-4419-1428-6 (last check 2021-03-25)
Jaques, P.; Andrade, A.; Jung, J.; Bordini, R.; Vicari, R.: Using pedagogical agents to support collaborative distance learning. In: Proceedings of the Conference on Computer Support for Collaborative Learning: Foundations for a CSCL Community, CSCL ’02, International Society of the Learning Sciences, 2002, pp. 546–547. https://dl.acm.org/doi/10.5555/1658616.1658713 (last check 2021-03-25)
Kim, S.; Eun, J.; Oh, C.; Suh, B.; Lee, J.: Bot in the bunch: Facilitating group chat discussion by improving efficiency and participation with a chatbot. In: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, CHI ’20, New York, NY, USA, 2020, pp. 1–13. Association for Computing Machinery. ISBN 9781450367080. doi: 10.1145/3313831.3376785. https://dl.acm.org/doi/10.1145/3313831.3376785 (last check 2021-03-25)
Kiy, A.; Lucke, U.; Zoerner, D.: An Adaptive Personal Learning Environment Architecture. In: Maehle, E.; Römer, K.; Karl, W.; Tovar, E. (Ed.): Architecture of Computing Systems – ARCS 2014, Springer International Publishing, Cham, 2014, pp. 60–71. ISBN 978-3-319-04891-8. https://link.springer.com/book/10.1007/978-3-319-04891-8 (last check 2021-03-25)
Kumar, A.; Singh, N.; Neelu, J.-A.: Learning styles based adaptive intelligent tutoring systems: Document analysis of articles published between 2001. and 2016. In: International Journal of Cognitive Research in Science, Engineering and Education (IJCRSEE), 5, 2017, pp. 83–98. doi: 10.5937/IJCRSEE1702083K. http://scindeks.ceon.rs/Article.aspx?artid=2334-847X1702083K (last check 2021-03-25)
Lave, J.; Wenger, E.: Situated Learning: Legitimate Peripheral Participation. Cambridge University Press, 1991.
Martin, F.; Chen, Y.; Moore, R. L.; Westine, C. D.: Systematic review of adaptive learning research designs, context, strategies, and technologies from 2009 to 2018. In: Educational Technology Research and Development, 68(4), 2020, pp. 1903–1929. ISSN 1556-6501. doi: 10.1007/s11423-020-09793-2. https://link.springer.com/article/10.1007%2Fs11423-020-09793-2 (last check 2021-03-25)
Menold, J.; Jablokow, K.: Exploring the effects of cognitive style diversity and self-efficacy beliefs on final design attributes in student design teams. In: Design Studies, 60, 2019, pp. 71–102. ISSN 0142-694X. doi: 10.1016/j.destud.2018.08.001 https://www.sciencedirect.com/science/article/abs/pii/S0142694X18300565?via%3Dihub (last check 2021-03-25)
Nakic, J.; Granic, A.; Glavinic, V.: Anatomy of Student Models in Adaptive Learning Systems: A Systematic Literature Review of Individual Differences from 2001 to 2013. In: Journal of Educational Computing Research, 51(4), , 2015, pp. 459– 489. doi: 10.2190/EC.51.4.e https://journals.sagepub.com/doi/10.2190/EC.51.4.e (last check 2021-03-25)
Newman, A.; Gates, B.; Fleming, B.; Sarkisian, L.: Learning to Adapt 2.0: The Evolution of Adaptive Learning in Higher Education. In: Technical report, Typton and partners, 2016. URL https://tytonpartners.com/library/learning-to-adapt-2-0-the- evolution-of-adaptive-learning-in-higher-education/ (last check 2021-03-25)
OECD. Education at a Glance 2020. Technical report, OECD, 2020. URL https://www.oecd-ilibrary.org/content/publication/69096873-en (last check 2021-03-25)
Osadcha, K.; Osadchyi, V.; Semerikov, S.; Chemerys, H.; Chorna, A.: The review of the adaptive learning systems for the formation of individual educational trajectory. CEUR Workshop Proceedings, 2732, 2020, pp. 547–558. ISSN 16130073. https://www.researchgate.net/profile/Hanna-Chemerys/publication/345948449_The_Review_of_the_Adaptive_Learning_Systems_for_the_Formation_of_Individual_Educational_Trajectory/links/5fb2b28ea6fdcc9ae05ae94d/The-Review-of-the-Adaptive-Learning-Systems-for-the-Formation-of-Individual-Educational-Trajectory.pdf (last check 2021-03-25)
Pérez, J. Q.; Daradoumis, T.; Puig, J. M. M.: Rediscovering the use of chat-bots in education: A systematic literature review. In: Computer Applications in Engineering Education, 28(6), Sept. 2020, pp. 1549–1565. doi: 10.1002/cae.22326. URL https://onlinelibrary.wiley.com/doi/10.1002/cae.22326 (last check 2021-03-25)
Pluut, H.; Curşeu, P. L.: The role of diversity of life experiences in fostering collaborative creativity in demographically diverse student groups. Thinking Skills and Creativity, 9, 2013, pp. 16–23. ISSN 1871-1871. doi: 10.1016/j.tsc.2013.01.002. https://www.sciencedirect.com/science/article/abs/pii/S1871187113000035?via%3Dihub (last check 2021-03-25)
Sarwar, S.; Qayyum, Z. U.; García-Castro, R.; Safyan, M.; Munir, R. F.: Ontology based E-learning framework: A personalized, adaptive and context aware model. In: Multimedia Tools and Applications, 78(24), 2019, pp. 34745–34771. ISSN 1573-7721. doi: 10.1007/s11042-019-08125-8 https://link.springer.com/article/10.1007%2Fs11042-019-08125-8 (last check 2021-03-25)
Schwendimann, B.; Rodriguez-Triana, M.; Vozniuk, A.; Prieto, L.; Boroujeni, M.; Holzer, A.; Gillet, D.; Dillenbourg, P.: Perceiving learning at a glance: A systematic literature review of learning dashboard research. In: IEEE Transactions on Learning Technologies, 10 (1), 2017, pp. 30-41. ISSN 1939-1382. doi: 10.1109/TLT.2016.2599522 https://ieeexplore.ieee.org/document/7542151 (last check 2021-03-25)
Seidel, N.; Rieger, C. M.; Walle, T.: Semantic textual similarity of course materials at a distance-learning university. In: Price, T. W.; Brusilovsky, P.; Hsiao, S. I.; Koedinger, K.; Shi, Y. (Ed.): Proceedings of 4th Educational Data Mining in Computer Science Education (CSEDM) Workshop co-located with the 13th Educational Data Mining Conference (EDM 2020), Virtual Event, July 10, 2020, volume 2734 of CEUR Workshop Proceedings. CEUR-WS.org, 2020. URL http://ceur-ws.org/Vol-2734/paper6.pdf (last check 2021-03-25)
Talaghzi, J.; Bennane, A.; Himmi, M. M.; Bellafkih, M.; Benomar A.: Online Adaptive Learning: A Review of Literature. Chapter Online Adaptive Learning: A Review of Literature, Association for Computing Machinery, New York, NY, USA, 2020, pp. 1–6. ISBN 9781450377331. URL https://doi.org/10.1145/3419604.3419759 (last check 2021-03-25)
Trausan-Matu, S.: Automatic support for the analysis of online collaborative learning chat conversations. In: Tsang, P.; Cheung, S. K. S.; Lee, V. S. K.; Huang, R. (Ed.): Hybrid Learning. Springer, Berlin, Heidelberg, 2010, pp. 383–394. ISBN 978-3-642-14657-2.
Vandewaetere, M.; Desmet, P.; Clarebout, G.: The contribution of learner characteristics in development of computer-based adaptive learning environments. In: Computers in Human Behavior, 27, 2011, pp. 118–130. https://doi.org/10.1016/j.chb.2010.07.038 https://www.sciencedirect.com/science/article/abs/pii/S0747563210002347?via%3Dihub (last check 2021-03-25)
Veiel, D.: Eine serviceorientierte Plattform für die Unterstützung kontextbasierter Adaption für Gruppen in gemeinsamen Arbeitsbereichen. PhD thesis, FernUniversität in Hagen, 2013. URL http://deposit.fernuni-hagen.de/2936/ (last check 2021-03-25)
Veiel, D.; Lukosch, S.; Haake, Jörg M.: Kontextbasierte Adaption gemeinsamer Arbeitsbereiche. In: Informatik-Spektrum, 34(2), 2011, pp. 120–133, 2011. ISSN 1432-122X. doi: 10.1007/s00287-010-0515-6 https://link.springer.com/article/10.1007%2Fs00287-010-0515-6 (last check 2021-03-25)
Vizcaíno, A.; Contreras, J.; Favela, J.; Prieto, M.: An adaptive, collaborative environment to develop good habits in programming. In: Gauthier, G.; Frasson, C.; VanLehn, K. (Ed.): Intelligent Tutoring Systems. Springer, Berlin, Heidelberg, 2000, pp. 262–271. ISBN 978-3-540-45108-2. https://link.springer.com/book/10.1007/3-540-45108-0 (last check 2021-03-25)
Xie, H.; Chu, H.-C.; Hwang, G.-J.; Wang, C.-C.: Trends and development in technology-enhanced adaptive/personalized learning: A systematic review of journal publications from 2007 to 2017. In: Computers & Education, 140, 2019, pp. 103599. ISSN 0360-1315. doi: 10.1016/j.compedu.2019.103599 https://www.sciencedirect.com/science/article/abs/pii/S0360131519301526 (last check 2021-03-25)