Language Learning in 3D Virtual World
Using Second Life as a Platform
urn:nbn:de:0009-5-31706
Abstract
Second Life (SL) is an ideal platform for language learning. It is called a Multi-User Virtual Environment, where users can have varieties of learning experiences in life-like environments. Numerous attempts have been made to use SL as a platform for language teaching and the possibility of SL as a means to promote conversational interactions has been reported. However, the research so far has largely focused on simply using SL without further augmentations for communication between learners or between teachers and learners in a school-like environment. Conversely, not enough attention has been paid to its controllability which builds on the embedded functions in SL. This study, based on the latest theories of second language acquisition, especially on the Task Based Language Teaching and the Interaction Hypothesis, proposes to design and implement an automatized interactive task space (AITS) where robotic agents work as interlocutors of learners. This paper presents a design that incorporates the SLA theories into SL and the implementation method of the design to construct AITS, fulfilling the controllability of SL. It also presents the result of the evaluation experiment conducted on the constructed AITS.
Keywords: e-learning; e-learning design; 3D MUVES; Second Life; language learning theories; communication task; interaction; negotiation of meaning; agent
Second Life (SL) is one of the multi-user virtual environments (MUVEs), which is a three dimensional virtual reality space. In SL, users can interact with each other through avatars. They can freely explore the virtual space, meet and talk with other people, initiate and participate in individual and group activities, create virtual property and services, and even trade these properties and services with one another. As of 2010, it has more than 21 million registered user accounts (“ Second Life,” n.d. ). To log in to SL, a software application called “Viewer” is used. In this application, a modeling tool and an object-oriented scripting language (Linden Scripting Language, LSL) are employed to build and control virtual objects.
The use of a MUVE like SL may change the nature of the learning experience, as it enables learners to simultaneously have various types of learning experiences, such as social, immersive, and creative experiences ( Vickers, 2010; Avatar Languages, n.d. ). In addition, SL is reported to improve attitudinal features of learners such as autonomy and motivation ( Cooke-Plagwitz, 2008 ; Hislope, 2008 ; Peterson, 2011 ). In short, learners in SL can freely interact with each other both in synchronous and asynchronous ways (social experience), create whatever objects they like and control them (creative experience), be absorbed in activities as if in the real world ( Cooke-Plagwitz, 2008 ; Dieterle and Clarke, 2007 )(immersive experience), and decide their courses of action in the world on their own (autonomy and motivation).
Owing to these merits, there have been numerous attempts to use SL as a platform for language teaching ( Forsythe, 2009 ; O´connor, 2010 ). The potential of 3D virtual worlds for language teaching is in the creation of the environments that may “facilitate language development” ( Peterson, 2010 ). However, as will be reviewed in the following chapter, current SL-based research such as Wang Song, Xia, and Yan (2009) and Hislope (2008) largely focused on simply using SL for learner-to-learner or teacher-to-learner communication in a school-like environment where SL is used as a communication tool for distance learning, while the controllability of SL to utilize the functions embedded in it has not been given sufficient attention. SL has many functions available for language learning such as playing recorded sounds, or creating objects which can perform human-like actions. The controllability of SL enhances these functions. Dieterle and Clarke (2007) stated that in MUVEs “researchers and designers can create scenarios with real-world verisimilitude that are safe, cost effective, and directly target learning goals” (p. 7), and they “have the potential to change the way students learn and the way teachers teach” ( cited in Cooke-Plagwitz, 2008 , p. 554). SL is programmed using LSL, which is a scripting language similar to C, PHP, and Perl. Using LSL, SL users can create content, i.e., design and control the environment. Making good scenarios and controlling learning environments based on second language acquisition (SLA) theories have the potential to change the way of language teaching and learning. It might also shed light on areas not considered in past SL-based research.
This paper first provides an overview of previous studies that used SL for language teaching, and summarizes their challenges and the functions of SL. Next, this paper proposes a design incorporating the latest SLA theories into SL to construct an automatized interactive task space (AITS), where robotic agents work as interlocutors of learners. Lastly, the results of an experiment on AITS, conducted to examine the effects on language learning, are presented and discussed.
Since the launch of the service of SL, there have been attempts to use it as a platform for language learning. Some of them are large-scale projects attempting to collect effective language learning methods. The AVALON project, the NIFLAR project, and Talk with Me by EU, and A Simil8 by Dublin University College are among them ( Hundsberger, 2009 ). These projects provide information on learning models and practices promoting SL in language learning. Noteworthy results are expected to be reported on the effective use of SL and on what aspects of language learning SL has an effect.
Individuals and groups of researchers have conducted studies focusing on the impact of using SL as a communication tool. Many of them have paid attention to learners` attitudes and motivations during conversational interactions in SL. The VirtualQuest model, proposed by Vickers (2010) , offers an enquiry-based approach where learners have the autonomy to create and perform their own tasks for communication, such as plays, videos, and holiday plans. Vickers' SL-based language school, Avatar Languages, attempts to attract learners from all over the world. In 2008, Hislope surveyed students learning Spanish in SL at a U.S. university and reported that SL helped them learn Spanish, specifically in conversational interactions. Wang, Song, Xia, and Yan (2009) , in cooperation with a U.S. university, developed an English language learning course in SL and reported that the Chinese students who had participated in the course positively evaluated SL as a platform for learning English. They also had positive attitudes toward SL and advocated its frequent use in the future.
On the other hand, some research results and surveys indicate shortcomings of SL. Hislope (2008) mentioned the difficulty of operating and navigating in SL. Cooke-Plagwitz (2008) mentioned that MUVEs are “too complicated for many educators to use” (p. 551). In reality, users need to take a fair amount of time to familiarize the structure of the Viewer interface to freely navigate an avatar and operate objects. Hislope also mentioned that in SL users are unable to read other users´ reactions because “body language and facial expressions are removed in the SL context” (p. 57). This may be a shortcoming of SL, but it should be noticed that SL has complementary methods to express emotions such as gestures, text-messaging and voice chat. Cooke-Plagwitz also points to the existence of undesirable badly-behaved individuals who disrupt class or a meeting in progress (2008, p. 552). Fortunately, the SL educator community shares tips for better inworld experiences: To prevent being victims of griefing (inworld vandalism), administrators of virtual lands (sims) have the option to close their sims to the public and allow access to vetted members only. Also, to prevent inappropriate encounters and content, best practices of inworld teaching suggest that instructors scout several locations before sending their students on exploration activities.
Based on previous research, it can be concluded that a lot of benefits can be obtained by using SL as a platform for language learning, although some drawbacks need to be overcome. 3D MUVEs' specifically appealing features promote students' motivation and attitude toward language learning and strengthened desire to continue to learn.
However, most of the empirical studies reviewed here were conducted in an environment where SL was simply used as a means of computer mediated communication in distance learning. In other words, these experiments were conducted in a school-like environment with a number of invited learners and teachers interacting with each other. It should be addressed, however, that the potential of SL is not confined to the role of an information transmitting tool. We can create intelligent objects, or agents which can be fully controllable using LSL built-in scripts and functions. If intelligent agents can help language learners to practice and improve their communication skills, the value of using SL for language learning would be augmented greatly.
As mentioned above, past research was conducted with little focus on expecting assistance from intelligent agents. SL can be perceived as a chaotic world full of unexpected happenings; however, the same openness of the platform allows for user creation and manipulation of the environment. To effectively utilize the world for language learning, the learning environment should be properly controlled based on SLA theories.
The goal of this research is to adopt two influential SLA theories, the Task-Based Language Teaching and the Interaction Hypothesis, into SL and to construct AITS. Based on these SLA theories, the design of how to incorporate the task structure and the structure of communicative interaction and meaning negotiation (See Section 4.2. ), and the implementation of the design by LSL programming are investigated (Figure 1). Whether the created learning space would be effective in language learning is also examined.
In AITS, agents work as interlocutors to learners. This space should be securely protected from other areas of SL and restricted to vetted learners and teachers. Learning should be fully controlled and guided by agents, and learners should be expected to acquire basic expressions and communicative competence through communication with agents.
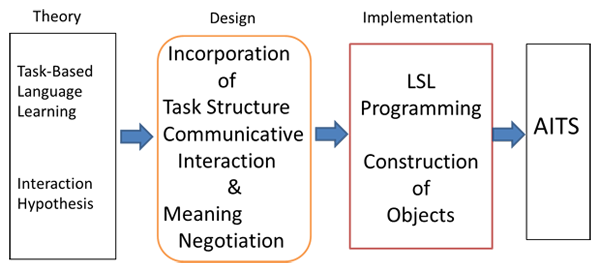
Figure 1 Designing and implementing SLA theories into SL
Thus, the following research questions will be investigated.
-
How can we design in SL the structure of a communication task, a communicative interaction, and meaning negotiation based on the SLA theories?
-
How can the design be implemented using LSL?
-
Is the created learning space effective in language learning?
Before we attempt to answer these questions, we need to clarify which SL functions are available to language learning and what the features of the above-mentioned SLA theories are. The following chapter will address these questions.
SL has a number of functions to be utilized for language learning:
-
you can create objects of any shape, color, and size, and allocate, transform, and transfer your own created objects,
-
you can give and take objects to/from avatars and objects, and delete your own created objects,
-
you can communicate with avatars and objects (agents) with text-messaging and voice chat and exchange stored messages,
-
you can play recorded sounds including voice,
-
you can manipulate LSL to program your intelligent agent.
Using these SL functions, it is possible to set up the environment with objects such as schools, classrooms, desks, and chairs necessary for a formal learning environment, and shops, parks, streets, etc., used for communication tasks in an naturalistic environment. In this environment, leaners can engage in various activities, such as exchanging text messages, listening to the recorded sounds, giving and taking things to/from other avatars and objects. In addition, it is possible to control these created objects and their actions by adding script command.
Thus, using LSL, you can embed in agents:
-
a sensor to sense the approach of avatars and objects,
-
a text recognition function to examine the text input,
-
a timer to start a specific action at a designated time,
and you can make agents respond to an avatar´s speech and actions by text-messaging or playing recorded sounds/voices.
In second language teaching, meaning-focused lessons and activities are emphasized. This was a reaction against insufficient learning outcomes of form-focused type of teaching adopted in the Grammar Translation method and the Audio-Lingual approach. Many language teachers adopt the Communicative Language Teaching (CLT), which has been one of the most influential language teaching methodologies. CLT emphasizes meaning, and as effective activities to improve communicative ability, communication tasks are recommended to be used. Communication tasks “hold a central place in current SLA research” ( Ellis, 2003 ). Thus, Task-Based Language Teaching is being advocated and language teachers are trying to introduce communication tasks in their lessons. The definition of a communication task varies among researchers and practitioners, but its essential characteristics are common. The present study, based on the definition by Skehan (1998), defines the constituents of a task as follows:
-
A task has a goal to be attained.
-
A task is primarily meaning-focused.
-
A task has some relationship to the real world.
-
A task involves communicative language use.
-
A task brings about some kind of outcome by completion.
In communication tasks, various types of interactions occur and learners often have difficulties understanding what their interlocutor says. This kind of misunderstandings occurs especially when the interlocutor makes an error in the use of the language. The interactions occurring in these occasions have been discovered to have specific patterns. Varonis and Gass (1985) showed an example of conversational exchange to explain the structure of the interaction, which has two stages: a trigger and a resolution. The former stage, trigger (T), involves a remark that causes a comprehension problem. The latter stage consists of an indicator of a problem (I), a response to the indicator (R), and an optional reaction to the response (RR).
Student 1: And what is your mm father´s job?
Student 2: My father is now retire. (T)
Student 1: Retired? (I)
Student 2: Yes. (R)
Student 1: Oh, yes. (RR)
(
Varonis and Gass, 1985
)
The Interaction Hypothesis states that the discourse work to resolve this type of non-understanding sequence is called the negotiation of meaning. In the negotiation of meaning, varieties of conversational strategies are used in the exchange, among which “Comprehension Checks,” “Confirmation Checks,” and “Requests for Clarification” are used very often. The use of these strategies leads to more positive evidence about the correct target language forms. Recasts, which are rephrased learners´ utterances by changing one or more sentence components, are also used.
The results of the Interaction Hypothesis research argue that the negotiation of meaning using these strategies, combined with the contribution of negative feedback (e.g., when a second language learner makes an error using the past tense, such as saying “He come yesterday,” a native speaker will say, “You have to use the past form when you say ‘yesterday’.”), modified input (i.e., foreigner talk and teacher talk, which are simplified versions of a language), and comprehensible input (i.e., input of a slightly higher level than the learner´s present proficiency level), facilitates language acquisition.
Thus the incorporation of these two theories, the Task-Based Language Teaching and the Interaction Hypothesis, can lead to the construction of learning environments that efficiently promote language acquisition. This is possible because learning in this environment entails communication tasks, especially the ones where meaning negotiation occurs with appropriate feedbacks from the interlocutors.
In order to incorporate the task structure into SL, the structure of a typical task conducted in a classroom was analyzed. A task performed in a classroom consists of three parts. The first part is an explanation of the task procedure by an instructor. The instructor provides an explanation of how the task proceeds by using a handout. Consider, for instance, a shopping task, which is an example task used in this study. Before starting a task, learners are explained as to where they are going, what they are going to buy, and how much money they have. The second part, which is the main part, is where the task is actually performed. In the case of a shopping task in a real classroom, learners interact with each other by forming, for example, two groups and taking either the shopper's role or the shopkeeper's role. The third and last part is where learners exchange information about what they have done. In the case of a shopping task, it will be the information about what they bought and how much they spent on shopping. This is usually done by way of presenting the goods they have obtained or reporting what they have done to the teacher or the whole class.
These three parts can be incorporated into an equivalent number of SL components. They are the initiation component, the task component, and the evaluation component. The initiation component is where the explanation of a task is given by an agent placed in a virtual classroom and embedded with recorded explanatory voices and text messages that are presented to learners in response to a learner´s utterance. The task component is where learners perform the task while interacting with an agent. This component has its own specific space containing items needed to conduct the task. In the case of a shopping task, a shop is built with target goods placed inside, where learners go, assume the role of a shopper, and interact with an agent to buy what is requested in the initiation component. The evaluation component is where learners report to an agent the task outcome or show what they have obtained (Figure 2).
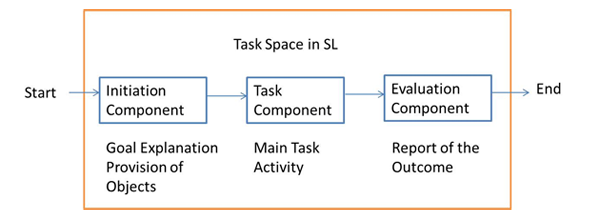
Figure 2 Incorporation of task components into SL
Before the advent of 3D MUVEs, conventional discourse analysis did not pay attention to learners´ motions. Transcribed texts of learners´ utterances were all the material used to analyze the interactions. However, most of the conversational interactions occurring in the real world contain motions as an initiating sign or a response to an utterance. In the conversation example below, X starts saying “A bird´s singing” because s/he hears a bird chirp. For learners in 3D MUVE, motions of this kind can be essential clues to sustain the interaction. If we can interpret the motions of learners and objects around us as elements of conversational interaction together with utterances, the method of communication analysis will surely be more sophisticated.
On the other hand, a conversational interaction proceeds in a linear order. It is impossible to understand the meaning of one cutout of utterance apart from the other parts of the conversation. In the example below, if one suddenly hears the second utterance of Y (“That one over there”), s/he won´t understand, because the cut-out utterance is out of context. Thus, utterances in a conversational interaction depend on context and it is not a simple task to take them apart into meaningful smaller units, which is required to incorporate them into SL by LSL programming.
X: (A bird chirps) A bird´s singing. What bird is it?
Y: (Pointing at a nearby tree) Look! Can you see a yellow one in that tree?
X: No. I can´t find it.
Y: Come with me. I´ll show you where it is. (Moving toward a tree and pointing at the bird) That one over there.
X: (Looking at the bird) Oh, now I can see it. It´s a parrot, isn´t it?
To cope with these two challenges, the interpretation of motion and the connection of context in a conversation, this study introduces two new notions, interaction unit (I-Unit) and environmental state (State). I-Unit is a combination of two utterances, which can contain motions such as gestures and movements. State is where one I-Unit is developed (i.e., one interaction occurs) in a specific environment in the 3D world. State is also where the negotiation of meaning occurs in relation to one I-Unit. I-Unit includes three different patterns. The first pattern is a combination of an utterance and its responsive utterance. The second is a combination of an utterance and its responsive motion (sometimes accompanied by an utterance). The third is a combination of a motion (sometimes accompanied by an utterance) and its responsive utterance. A combination of a motion in response to a motion is possible, but since the present study focuses on “verbal language” learning, this pattern is not considered.
-
Speech →Speech
-
Speech →Motion ( sometimes with Speech)
-
Motion ( sometimes with Speech)→Speech
The following is an example of a typical conversation that takes place during shopping. The explanations in the parentheses are the motions typically performed along with the utterances. The bold letters represent more essential parts of combined reactions or responses, without which the interaction breaks down.
Shopper: (Comes in the shop)
Shopkeeper: “Hello. Can I help you?”
Shopper: “Yes. Do you have apples?”
Shopkeeper: “How many would you like?”
Shopper: “Three apples, please.”
Shopkeeper: (Offers apples) “Here you are.”
Shopper: (Taking apples) “How much are they?”
Shopkeeper: “Four dollars, please.”
Shopper: (Offers the money) “Here you are.”
Shopkeeper: “Thank you.”
Shopper: “Good-bye.”
At a first glance, this flow of conversation, which is rich in different types of interactions, seems too complicated to be implemented by LSL because the utterances in the lower lines naturally include all the results of the utterances or motions that occurred earlier. However, by using the notions of I-Unit and State, this conversation can be analyzed and expressed in very simple forms (Figure 3). The transition of the States (e.g. State 1 to State 2) entails successful completions of the previous States and the lower States naturally entail the results of the previous States.
Thus the combination of the three types of I-Unit and the transitions of the States enable economical and efficient description of the LSL scripts that control the actions of the agents in SL. Figure 3 shows how the interactions illustrated above are described using I-Unit and States when a learner (shopper), interacts with an agent (shopkeeper).
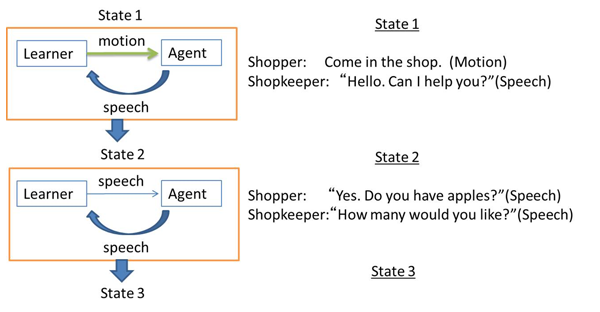
Figure 3 I-Unit interactions and State transitions
As stated in section 4.2. , when a communication problem occurs, such as misunderstanding of meaning, certain meaning negotiation strategies are usually used in a conversation. Therefore, it is also necessary for these strategies to properly function during the interactions between a learner and an agent. According to the Interaction Hypothesis, there are three or four different types of meaning negotiation strategies used in conversational interactions: Comprehension Checks, Confirmation Checks, Requests for Clarification, and Recasts as stated in section 4.2.
First, while considering these strategies, three different actions were assumed to be taken by a learner when s/he didn´t understand what an agent said or motioned: no response, a request for repetition, and an inappropriate response. Then, the processing methods of each of these actions were individually considered in order to keep the interaction going. As a result, it was decided that if there was no response for a certain period of time (e.g. 30 seconds), or if there was a request for repetition, an agent would repeat the previous utterance by recorded voice. If a learner´s response was inappropriate, it would recast exactly what the learner said, adding a question mark (“?”) to the end of the utterance, by text-messaging. In conversations between a learner and an agent in AITS, a learner always speaks by text-messaging and the avatar usually speaks with recorded voices, except for recasts, which are made by text-messaging. As a result, two kinds of feedback, repetition and recast (confirmation check), were incorporated as responses by an agent.
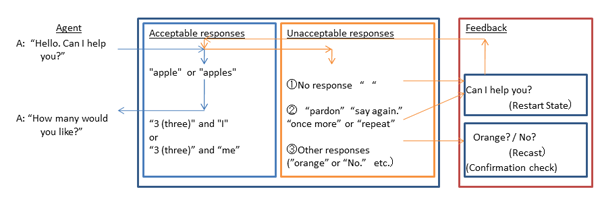
Figure 4: Mechanism to promote interaction
Figure 4 shows the mechanism of the negotiation of meaning. This represents the second State of the shopping conversation exemplified in the previous section. It illustrates that when the agent senses the learner´s motion of entering the shop, the agent responds to a learner by saying, “Hello. Can I help you?”. At the same time, the LSL script transitions to the next State. Then, if the learner utters any of the strings of the expected sentence, such as “have apple” or “have apples,” the LSL script makes the agent say, “How many would you like?” If he keeps silent for a certain period of time, or his response includes parts of the request for repetition, such as “Pardon?,” “Say again,” and “Repeat” (Clarification Request), it reverses the flowing direction of the script and makes the agent repeat the utterance in the previous State. If the learner gives an unacceptable response, like “No,” the LSL script orders the agent to recast what the learner said with a question mark added to the learner´s utterance (“No?”) (Recast / Confirmation Check), and the LSL script resumes from the start of the State and the agent waits for another utterance by the learner. This cycle is repeated as long as unacceptable responses are given by the learner. Thus, the interaction will be frequently repeated for the learner to notice the mistaken form of their utterance and enhance language acquisition.
The previous chapter introduced the design to incorporate the SLA theories, i.e. the incorporation of the task structure, the interaction structure and the mechanism of meaning negotiation. The next step is to implement the design into SL and to construct AITS. Following is the implementation method of the task structure.
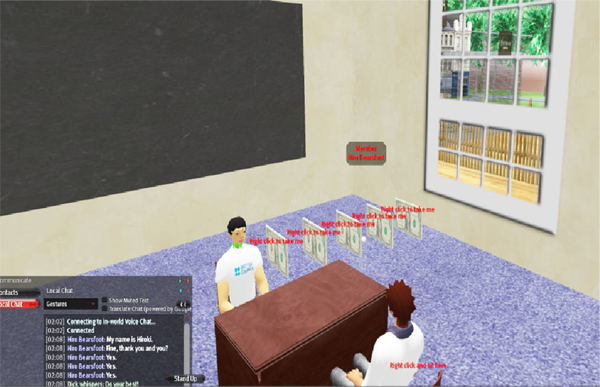
Figure 5 the initiation component

Figure 6 the task component

Figure 7 the evaluation component

Figure 8 Classroom A and B
As stated above, there are three components in the task structure. The first is the initiation component called Classroom A (Figure 5), where a teacher agent, called Dick, instructs a leaner about what to do and provides necessary things to perform the task. In the case of a shopping task, the learner is instructed to follow the directions shown and go to a shop, buy three apples, and then go to neighboring Classroom B to report the outcome. The second component is the task component, or the space for the main task (Figure 6). This is where the learner performs the designated task by interacting with an agent prepared specifically for the task. If s/he succeeds in the communication with proper motions, s/he can successfully pass through this component. In case of a communication breakdown, the above-mentioned interaction sustaining mechanism begins functioning to help modify the learner´s utterance. The last component is the evaluation component which is Classroom B (Figure 7), where another agent teacher called Eve evaluates the outcome of the task. The learner is asked to show what s/he has obtained in the task. If s/he can successfully answer her questions about the content of the conversation between the learner and the agent in the task component, the task is completed. This task structure would be valid to any other types of task, such as “Showing the way”, “Eating at a restaurant”, etc.
Figure 9 demonstrates the simplified LSL description of the interaction structure and the mechanism of the negotiation of meaning at the start of the conversation in the task component ( section 5.2.1. ). Each state consists of one I-Unit and (if necessary) the embedded mechanism of the negotiation of meaning. The agent´s responses can be easily controlled by changing the contents of the messages (message 1 and 2, in this example). Furthermore, the difficulty level of the conversation task can be coordinated by changing the expected contents of the learner´s utterances (utterance 1 and 2, in this example).
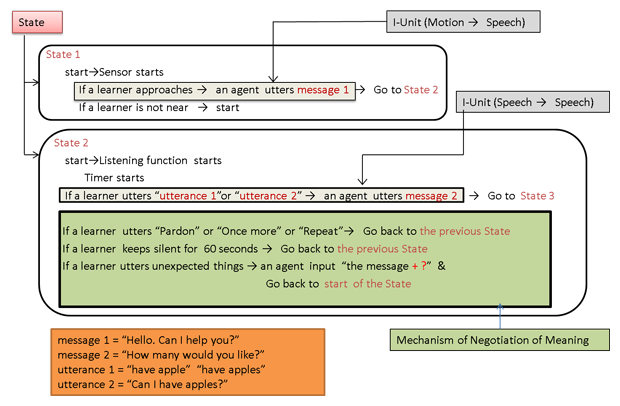
Figure 9: Simplified LSL description of the interaction structure and mechanism of the negotiation of meaning
Thus the agents are programmed that they always watch or listen to learner avatars approaching or chatting text messages, and this makes them respond and react to learner avatars as soon as they notice them approaching or they type any strings of letters. Thus, if a learner enters the initiation component, or Classroom A (Figure 5), and approaches Dick, he starts to speak to him/her, “Hello. I´m Dick. What´s your name?” If an agent in the task component notices a learner type a phrase like “have apple(s)”, he replies using recorded voice like “How many would you like?” In addition, learners perform the task not just by communicating with the agents but by experiencing as they usually do in the real world; taking and giving objects such as goods and money. In the same way in the evaluation component or Classroom B (Figure 7), Eve starts to say, “Hello. What did you get?” when she notices a learner approach.
Using the constructed AITS [1], a pilot experiment was conducted to evaluate the system.
Ten university students participated in the experiments. The purpose of the experiment was to investigate the usefulness and the deficits (if any) of AITS, by examining the number of occurrences of the negotiation of meaning during the conversation, whether learners completed the task, how long it took to complete and what their evaluations were after the experiment. Individual participants came to the research room and experienced AITS by operating an avatar prepared by the authors. First, they were given an explanation about the experiment, what they should do to complete the task and how they should operate the avatar before the task. After the experiment, a post-survey questionnaire was used to evaluate AITS. An assessment device to record users´ logs was installed in a remote server to analyze the quantitative data: task completion, the number of occurrences of the negotiation of meaning and the time needed to complete the task.
Based on the analysis of the recorded log in the assessment device, six out of the ten participants completed the task and the average completion time for the task was about 12 minutes. Of the six participants who completed the task, two succeeded without using the negotiation of meaning. They seemed to have no difficulty understanding the agents´ utterances and, after only one listening, completed the task without any communication breakdown. The other four successful participants completed the task using the negotiation of meaning. Of the four participants who abandoned the task, three did not try to negotiate the meaning and as a result had to stop the learning process. This was probably because they had not acquired strategies that should be used in case of communication problems. One participant tried to negotiate the meaning, but did not receive beneficial feedback because he erroneously typed “perdon” instead of “pardon.” As for the task component, or the main task component, only one participant managed to use the meaning negotiation strategy.
The results of the survey shows that more than 70% of the participants thought learning on AITS was interesting as well as difficult, and that they would like to learn on AITS again. More than 50% of the participants felt learning on AITS was more fun than learning in a classroom; however 40% of them thought that this method of learning could not be said to be more effective. This result can be interpreted that AITS promoted motivation for learning because of its immersive nature despite the task being difficult. However, it still has a challenge to be solved in terms of learning effects. It should be also noted that out of the four participants who failed, two answered that operating the avatar was too difficult and did not understand what they should do. This is related to technological problems and confirms previous research results ( Hislope, 2008 ; Cooke- Plagwitz, 2008 ).
The free-text descriptions about the advantages of AITS indicate that the merits of AITS are its life-like virtuality, autonomy and ability to provide repeated responses to learners. The followings are some examples of the descriptions.
Q: What are the advantages of AITS?
Participant A: I was able to freely operate my avatar and learn English with pleasure.
Participant B: I was able to study as if I were in a foreign country and it was possible to freely move my avatar around.
Participant C: I was able to ask for agents‟ repetition as many times as I wanted, so I understood what I would do next.
Participant D: The situation was realistic and I thought I could apply the experience to the real world.
This study focused on the fulfillment of controllability of SL and designed the method of incorporating the SLA theories into SL. The design was implemented through the creation and the allocation of objects which are needed to practice tasks and the programming of the interaction structure using the notions of I-Unit and State and the meaning negotiation structure by LSL. Thus an automatized interactive task space called AITS was constructed, where learners can exercise communication tasks while negotiating meanings with agents. An example space for performing a shopping task was created for an evaluation experiment, which was conducted with 10 university students. The result of the questionnaire showed that more than 70% of the participants positively evaluated the system and that they would like to continue their study in AITS. On the other hand, there were participants who couldn´t complete the task and abandoned it because of some operational problems, an excessively difficult level of the task and lack of knowledge of communication strategies. The findings obtained in this study will be the basis for further research on the improved version of AITS.
Avatar Languages. (n.d.). http://www.slideshare.net/AvatarLanguages.com/presentation-of-avatar-languages?from=ss_embed (last check 2011-12-06)
Cooke-Plagwitz, J.: New Directions in CALL: An Objective Introduction to Second Life. In: CALICO Journal, 25(3), 2008, pp. 547-557.
Dieterle, E.; Clarke, J.: Multi-user Virtual Environments for Teaching and Learning. In: Pagani, M. (Ed.): Encyclopedia of multimedia technology and networking. (2nd ed).Idea Group, Inc., Hershey, PA, 2007.
Ellis, R.: Task-based Language Learning and Teaching. Oxford University Press. Oxford, 2003.
Forsythe, E.: Give your Language Class a Second Life [PowerPoint slides]. Retrieved from http://www.slideshare.net/EdoForsythe/give-your-language-class-a-second-life , 2009. (last check 2011-12-06)
Hislope, K.: Learning in a Virtual World. In: The International Journal of Learning, 15, 2008, pp. 51-58.
Hundsberger, S.: Foreign language learning in Second Life and the implications for resource provision in academic libraries. In: A report for the Arcadia Fellowship Programme at Cambridge University Library. 2009. Retrieved from http://www.dspace.cam.ac.uk/handle/1810/221921 (last check 2011-12-06)
O’Connor, E.: Using Second Life in Foreign Language Instruction-practical advice [PowerPoint slides]. 2010. Retrieved from http://www.slideshare.net/eoconnor/using-second-life-in-foreign-language-instructionpractical-advise (last check 2011-12-06)
Peterson, M.: Learner Participation patterns and strategy use in Second Life: an exploratory case study. In: ReCALL: European Association for Computer Assisted Language Learning 22(3), 2010, pp. 273-292.
Peterson, M.: Towards a Research Agenda for the Use of Three-Dimensional Virtual Worlds in Language Learning. In: CALICO Journal, 29(1), 2011, pp. 67-80.
Second Life. (n.d.). In: Wikipedia. Retrieved from http://en.wikipedia.org/wiki/Second_Life . (last check 2011-12-06)
Skehan, P.: A Cognitive Approach to Language Learning. Oxford University Press. Oxford, 1998.
Avatar Languages. (n.d.). 3D Virtual Worlds for Language Learning. Rerieved from http://www.slideshare.net/AvatarLanguages.com/3d-virtual-worlds-for-language-learning . (last check 2011-12-06)
Varonis, E.; Gass, S.: Non-native /Non-native Conversations: A Model for Negotiation of Meaning. In: Applied Linguistics. 6, 1985, pp. 71-90.
Vickers, H.: VirtualQuests: Dialogic Language Learning with 3D Virtual Worlds. In: CORELL: Computer Resources for Language Learning 3, 2010, pp. 75-81.
Wang, C.; Song, H.; Xia, F.; Yan, Q.: Integrating Second Life into an EFL Program: Students´ perspectives. In: Journal of Educational Technology Development an Exchange, 2(1), 2009, pp. 1-16.